Eliza : l'ancêtre des chatbots modernes comme ChatGPT
Un peu d'histoire. 1966. Joseph Weizenbaum crée Eliza, le premier chatbot de l'histoire. Comment cette découverte il y a 60 ans a t-elle bouleversée l'informatique et le rapport entre humains et machines ? C'est ce que vous allez comprendre dans cet article. Bonne lecture :).
-

- Dernière modification
13 janvier 2026 - 7 minutes de lecture
Un programme informatique capable de discuter avec vous comme un thérapeute, en reformulant vos phrases pour vous faire réfléchir, c'était l'idée de ce professeur du MIT. En 1966, alors que les ordinateurs occupaient des salles entières et que l'IA n'était qu'un rêve de science-fiction, Joseph Weizenbaum, professeur au MIT, crée Eliza. Ce chatbot primitif, inspiré d'un psychothérapeute rogerien (du nom du thérapeute Carl Rogers), trompe des utilisateurs en simulant une conversation humaine. Certains y voient même une intelligence réelle, déclenchant des débats éthiques qui résonnent encore aujourd'hui avec des outils comme ChatGPT.
Dans cet article, nous découvrirons Eliza comme le précurseur des chatbots modernes. Nous décortiquerons son mécanisme technique simple mais ingénieux, le replacerons dans le contexte technologique et sociétal des années 1960, et tracerons l'évolution spectaculaire vers les modèles d'IA générative actuels. Pourquoi cela importe-t-il ? Parce que comprendre ces racines aide à appréhender les innovations rapides en IA, des assistants vocaux aux LLM comme GPT-4 ou Claude 3. En 2026, avec des avancées comme Grok 4 ou Gemini 2.0, cette histoire nous rappelle que l'IA n'est pas née d'hier, mais d'expériences audacieuses qui ont pavé la voie.
Qu'est-ce qu'Eliza ?
Eliza est souvent considérée comme le premier chatbot de l'histoire. Développé par Joseph Weizenbaum entre 1964 et 1966 au Massachusetts Institute of Technology (MIT), ce programme informatique simulait une conversation avec un psychothérapeute. Son nom est inspiré d'Eliza Doolittle, le personnage de Pygmalion qui apprend à parler correctement, symbolisant l'idée d'un ordinateur "apprenant" le langage humain.
À l'époque, Eliza fonctionnait sur un ordinateur PDP-1, un mastodonte technologique. Elle n'était pas conçue pour être "intelligente" au sens moderne, mais pour démontrer comment un programme pouvait manipuler le langage naturel. Weizenbaum l'a programmée en utilisant le langage SLIP (Symmetric List Processor), une extension de Fortran, pour créer des scripts qui répondaient aux entrées utilisateur.
Pourquoi un thérapeute ? Weizenbaum s'est inspiré de la thérapie non directive de Carl Rogers, où le thérapeute reformule les déclarations du patient pour encourager l'introspection. Eliza ne comprenait pas vraiment le sens ; elle se contentait de patterns pour générer des réponses. Pourtant, des tests ont montré que des personnes non averties se confiaient à elle, croyant parler à un humain. Cela a mené à l'"effet Eliza", un phénomène où les humains projettent de l'intelligence sur des machines.
Pour illustrer, voici un exemple de conversation typique avec Eliza (basé sur des archives historiques) :
- Utilisateur : "Je me sens déprimé."
- Eliza : "Pourquoi dites-vous que vous vous sentez déprimé ?"
- Utilisateur : "Parce que ma famille me manque."
- Eliza : "Votre famille joue-t-elle un rôle important dans votre vie ?"
Ce simple échange révèle la magie d'Eliza : elle transforme l'interaction en une illusion de compréhension.
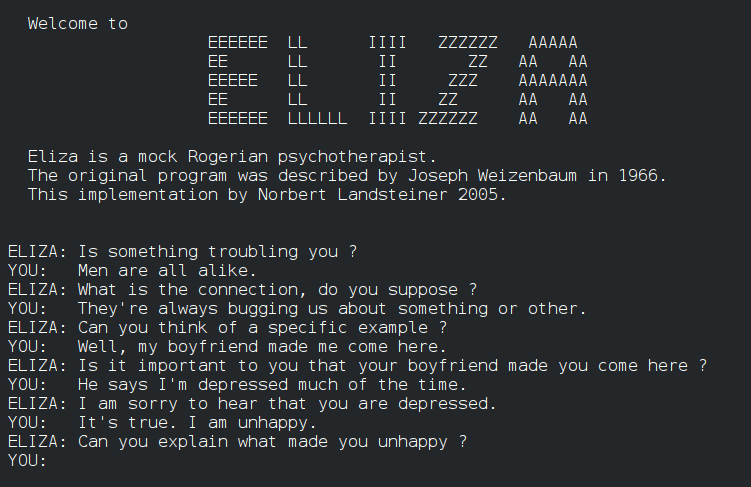
Voici l'interface d'Eliza créé en 2005 représentant une conversation avec le Chatbot.
Comment fonctionnait Eliza techniquement ?
Plongeons dans les rouages d'Eliza. Contrairement aux LLM actuels comme ChatGPT, qui s'appuient sur des réseaux de neurones et des milliards de paramètres, Eliza était un système "rule-based", basé sur des règles prédéfinies et du "pattern matching".
Les principes de base
Eliza analysait l'entrée utilisateur en cherchant des motifs (patterns) dans les phrases. Par exemple, si la phrase contenait "Je suis [quelque chose]", elle la reformulait en "Pourquoi êtes-vous [quelque chose] ?". Cela reposait sur ces 3 principes :
- Décomposition :Eliza décomposait la phrase en mots-clés. Elle utilisait une liste de priorités pour identifier des termes comme "mère", "famille" ou "rêve", qui déclenchaient des réponses spécifiques.
- Recomposition : Une fois le pattern identifié, elle appliquait une règle pour générer une réponse. Par exemple, "Je me souviens de X" devenait "Pensez-vous souvent à X ?".
- Scripts : Le script le plus célèbre, DOCTOR, contenait environ 200 règles. Si aucun pattern ne matchait, Eliza tombait sur des réponses génériques comme "Pouvez-vous développer ?" ou "Dites-m'en plus."
Techniquement, cela impliquait :
- 1. Lecture de l'entrée : L'utilisateur tapait une phrase via un terminal.
- 2. Normalisation : Suppression de la ponctuation, mise en minuscules.
- 3. Matching : Comparaison avec une liste de patterns classés par priorité (de 0 à 4, 4 étant le plus bas).
- 4. Transformation : Application d'une règle pour inverser les pronoms (je -> vous, mon -> votre) et assembler la réponse.
- 5. Mémoire contextuelle basique : Eliza gardait en mémoire certains éléments pour des références futures, comme des noms mentionnés.
Weizenbaum a décrit cela dans son papier de 1966, "ELIZA—A Computer Program for the Study of Natural Language Communication Between Man and Machine", publié dans Communications of the ACM. Le code source, disponible aujourd'hui sur des archives comme GitHub, montre une simplicité élégante : environ 200 lignes de code pour la version de base.
Limites techniques
Eliza n'apprenait pas ; elle n'avait pas de machine learning. Si l'entrée ne matchait rien, elle bouclait sur des phrases neutres. Cela contrastait avec les idées de l'époque sur l'IA forte, inspirées du test de Turing (1950), où une machine devait tromper un humain.
Malgré sa simplicité, Eliza a influencé la recherche en traitement du langage naturel (NLP). Elle démontrait que des règles syntaxiques suffisaient à créer une illusion d'intelligence, sans compréhension sémantique.
Le contexte de l'époque : les années 1960 et les débuts de l'IA
Pour apprécier Eliza, replaçons-la dans les années 1960, une décennie charnière pour l'informatique et l'IA.
L'environnement technologique
Les ordinateurs étaient énormes et coûteux. Le PDP-1 du MIT, sur lequel tournait Eliza, coûtait environ 120 000 dollars (équivalent à plus d'un million d'euros aujourd'hui). Pas d'internet, pas de cloud : tout se faisait en batch processing ou via des terminaux Teletype. Comprenez : c'était très répétitif.
L'IA émergeait avec des pionniers comme Alan Turing, John McCarthy (qui a inventé le terme "IA" en 1956) et Marvin Minsky. Le Dartmouth Workshop de 1956 avait lancé l'IA comme discipline, promettant des machines pensantes d'ici 20 ans. Mais les fonds ARPA (précurseur de DARPA) finançaient des projets ambitieux, comme des systèmes experts. Bon, cela a pris un peu plus de temps, mais l'idée était là.
Eliza arrivait au milieu de cela, mais Weizenbaum la créa comme une critique. Il voulait montrer les limites de l'IA, pas la glorifier. Ironiquement, des secrétaires du MIT demandaient à être seules avec l'ordinateur pour des "séances privées" !
Le contexte sociétal et éthique
Les années 1960 étaient marquées par la Guerre Froide, la course à l'espace et des mouvements sociaux. L'IA suscitait de l'espoir (fin de la pauvreté via l'automatisation) mais aussi de la peur (perte d'emplois, machines trop intelligentes). Finalement, assez proche des préoccupations d'aujourd'hui. Weizenbaum, un juif autrichien ayant fui les nazis, était sensible aux implications éthiques. Dans son livre de 1976, "Computer Power and Human Reason", il regrettait qu'Eliza ait été prise au sérieux, craignant que l'IA déshumanise les interactions.
Statistiquement, l'IA des années 60 était naissante : moins de 100 chercheurs mondiaux, des budgets modestes... Comparé à 2026, où l'IA pèse des billions d'euros (marché mondial estimé à 500 milliards d'euros selon Statista), c'est un monde à part.
L'évolution des chatbots de 1966 à aujourd'hui
Depuis Eliza, les chatbots ont connu une métamorphose, passant de règles statiques à des modèles apprenants. Traçons cette évolution en 4 étapes clés.
1. Les années 1970-1980 : améliorations du rule-based
- PARRY (1972) : Créé par Kenneth Colby à Stanford, PARRY simulait un patient paranoïaque. Plus complexe qu'Eliza, il intégrait des émotions et une "mémoire" pour des réponses cohérentes. Des psychiatres l'ont confondu avec un humain lors de tests.
- Systèmes experts : Dans les années 80, des outils comme MYCIN (diagnostic médical) appliquaient des règles à grande échelle, mais restaient domain-specific.
2. Les années 1990-2000 : l'ère des bots conversationnels
- ALICE (1995) : Développé par Richard Wallace, ALICE (Artificial Linguistic Internet Computer Entity) gagnait le Loebner Prize (inspiré du test de Turing). Basé sur AIML (Artificial Intelligence Markup Language), il étendait le pattern matching d'Eliza avec des milliers de règles.
- SmarterChild (2001) : Sur MSN Messenger (petit coup de vieux aux trentenaires et + ;)), ce bot répondait à des questions simples, préfigurant les assistants mobiles.
3. Les années 2010 : intégration de l'apprentissage automatique (machine learning)
- Siri (2011) et Alexa (2014) : Apple et Amazon intègrent le NLP et la reconnaissance vocale. Ces assistants hybrident "rules" et Machine Learning pour des tâches comme la météo ou les rappels.
- Watson d'IBM (2011) : Gagnant de Jeopardy!, il montre le potentiel du deep learning pour le langage.
4. Les années 2020 : l'essor des LLM
En 2022, OpenAI lance ChatGPT, basé sur GPT-3.5, un modèle avec 175 milliards de paramètres entraîné sur des téraoctets de données. Contrairement à Eliza, ChatGPT utilise des transformers (architecture de 2017 par Google) pour prédire des séquences de mots avec contexte.
Evolution clé :
- De statique à dynamique : Eliza avait des règles fixes ; les LLM apprennent de données massives via backpropagation.
- Échelle : Eliza : 200 lignes de code. ChatGPT : des data centers entiers, coûtant des millions d'euros en entraînement.
- Capacités : Eliza reformulait ; les LLM comme Claude (Anthropic) ou Gemini (Google) génèrent du code, des poèmes, ou analysent des images.
- En 2026 : Mises à jour comme GPT-5 (annoncé en 2025, avec multimodalité) ou Grok 4 (xAI) intègrent l'IA en temps réel, avec des prix accessibles (abonnements à partir de 20 euros/mois pour ChatGPT Plus).
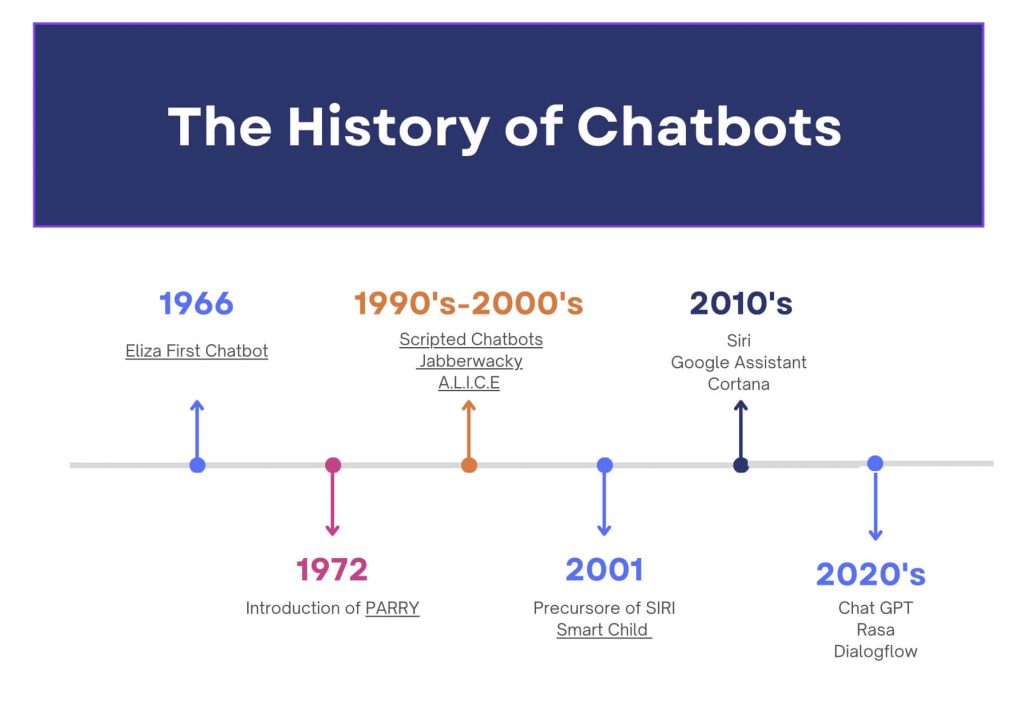
Timeline de l'évolution des chatbots d'Eliza à ChatGPT en 2026 (Source et crédits image : https://raffle.ai/newsroom/the-history-of-chatbots)
Conclusion sur Eliza
Eliza, ce chatbot de 1966, reste un jalon dans l'histoire de l'IA : un système simple qui a révélé notre propension à anthropomorphiser les machines. Techniquement basé sur du pattern matching, il contrastait avec le contexte naissant de l'IA des années 60, marqué par l'optimisme et les limites hardware. L'évolution vers des LLM comme ChatGPT, Claude ou Gemini illustre un bond : de règles fixes à des modèles apprenants, transformant l'IA en outil quotidien pour entrepreneurs et marketeurs.