44 % des citations de ChatGPT viennent du premier tiers de vos articles : ce que ça change pour le GEO
Une étude portant sur 1,2 million de réponses ChatGPT vient de confirmer ce que beaucoup pressentaient sans pouvoir le mesurer : les IA génératives ne lisent pas vos contenus comme un lecteur patient. Elles fonctionnent comme un rédacteur en chef pressé. 44,2 % des citations de ChatGPT proviennent du premier tiers d'un article. Ce chiffre bouleverse les règles de rédaction pour le GEO (Generative Engine Optimization) — et donne des leviers concrets pour améliorer votre visibilité dans les réponses de l'IA.
-

- Dernière modification
23 février 2026 - 7 minutes de lecture
📋 Sommaire ►
- Qu'est-ce que le GEO et pourquoi cette étude le change ?
- Le « ski ramp » : comment ChatGPT lit un article
- À l'intérieur des paragraphes : l'IA lit plus en profondeur qu'on ne le croit
- Les 5 caractéristiques du contenu cité par ChatGPT
- Ce que ça change concrètement dans votre façon d'écrire
- Les limites à garder en tête
- Conclusion : la « taxe de clarté » que le GEO impose aux rédacteurs
- Sources et références
- Questions fréquentes sur les citations de ChatGPT
Qu'est-ce que le GEO et pourquoi cette étude le change ?
Le GEO (Generative Engine Optimization) est l'ensemble des pratiques qui visent à optimiser un contenu pour être cité par les intelligences artificielles génératives : ChatGPT, Claude, Gemini, Perplexity... À la différence du SEO classique qui vise un positionnement dans Google, l'objectif du GEO est d'apparaître dans les réponses générées par les LLM (Large Language Models, ou modèles de langage de grande taille) quand un utilisateur pose une question.
Jusqu'à présent, les recommandations GEO reposaient surtout sur des intuitions et des expériences empiriques. Cette nouvelle étude du consultant Kevin Indig, publiée le 16 février 2026 dans sa newsletter Growth Memo, change la donne : pour la première fois, elle quantifie avec précision où dans un article ChatGPT puise ses citations, et quelles caractéristiques linguistiques déclenchent une citation.
La méthodologie est solide : 3 millions de réponses ChatGPT, 30 millions de citations analysées, dont 18 012 citations vérifiées et isolées pour l'analyse positionnelle. La valeur p (une mesure statistique qui indique à quel point un résultat est fiable — une valeur proche de 0 signifie que le hasard ne peut pas expliquer les résultats) de l'analyse est de 0,0 : les résultats sont statistiquement indiscutables.
Le « ski ramp » : comment ChatGPT lit un article
La découverte la plus marquante de l'étude est ce qu'Indig appelle le « ski ramp » — un terme anglais qui signifie littéralement « rampe de ski ». Il décrit la forme de la courbe de distribution des citations dans un article : très haute au début, puis qui descend progressivement, à l'image du profil d'un saut à ski vu de côté.
Concrètement, voici comment se répartissent les citations :
- Premier tiers de l'article (0-30 %) : 44,2 % des citations. C'est là que ChatGPT va puiser en priorité. L'introduction, la définition du sujet, les premières conclusions : tout ce que vous placez ici a 2,5 fois plus de chances d'être cité que le reste.
- Milieu de l'article (30-70 %) : 31,1 % des citations. La partie développement reste importante, mais avec une attention nettement plus faible.
- Dernier tiers (70-100 %) : 24,7 % des citations, avec une chute brutale dans la zone pied-de-page (90-100 %). En revanche, une section « Conclusion » ou « Résumé » juste avant le pied-de-page capte encore de l'attention.
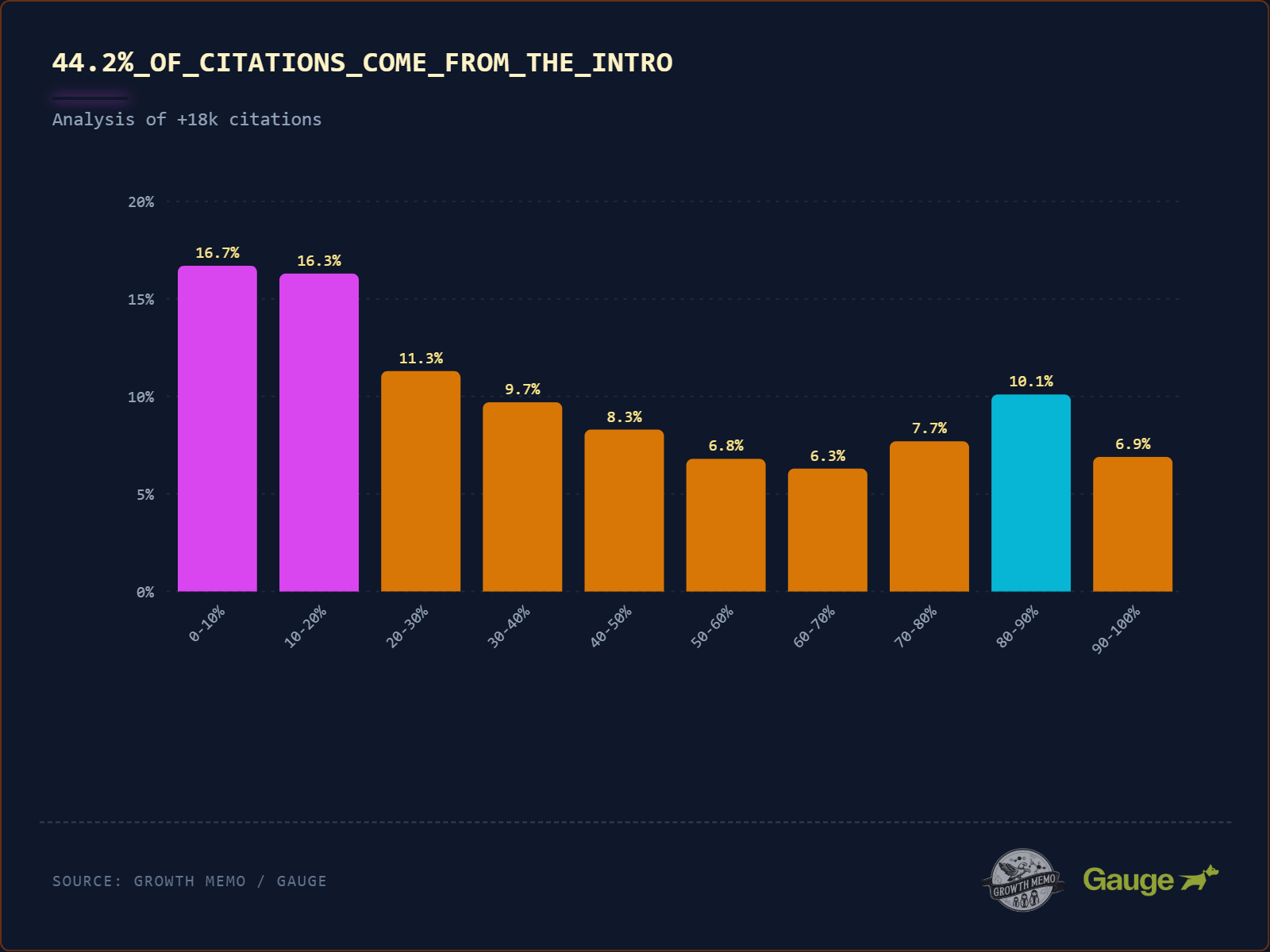
Pourquoi ce schéma ? L'explication tient à la façon dont les LLM ont été entraînés. Ces modèles ont ingéré des millions d'articles journalistiques et de publications académiques, qui suivent tous le principe du « BLUF » (Bottom Line Up Front, ou « la conclusion d'abord »). L'IA a donc appris que l'information la plus importante d'un texte se trouve généralement au début. Elle établit son cadre de compréhension rapidement, puis interprète le reste à travers ce prisme initial.
À l'intérieur des paragraphes : l'IA lit plus en profondeur qu'on ne le croit
Une nuance importante vient enrichir ce tableau. Si ChatGPT favorise massivement le début des articles, son comportement à l'intérieur d'un paragraphe est plus équilibré. L'analyse de 1 000 contenus à forte densité de citations révèle que :
- 53 % des citations viennent du milieu d'un paragraphe, c'est-à-dire de phrases qui ne sont ni la première ni la dernière.
- 24,5 % viennent de la première phrase d'un paragraphe.
- 22,5 % viennent de la dernière phrase.
Cela signifie que ChatGPT ne se contente pas de lire la première ligne de chaque bloc de texte. Il cherche la phrase qui contient le plus d'informations utiles — ce qu'Indig appelle le « information gain » (le gain d'information, c'est-à-dire la phrase la plus complète et la plus riche en données pertinentes), quelle que soit sa position dans le paragraphe. La leçon pratique : inutile de forcer votre point clé en première phrase de chaque paragraphe. Mieux vaut soigner la densité d'information sur l'ensemble du paragraphe, en particulier dans les premiers 20 % de la page.
Les 5 caractéristiques du contenu cité par ChatGPT
Au-delà de la position dans l'article, l'étude identifie cinq traits linguistiques qui augmentent significativement les chances d'être cité. Ce sont en quelque sorte les signaux de qualité que l'IA reconnaît dans un contenu.
1. Un langage définitoire
Les passages cités sont près de deux fois plus susceptibles de contenir des formulations de type définition : « X est… », « X désigne… », « X se réfère à… ». La raison est technique : dans la base de données vectorielle d'un LLM (une base de données qui stocke les informations sous forme de représentations mathématiques pour en comprendre le sens), le verbe « être » constitue un pont fort entre un concept et sa définition. Quand un utilisateur demande « qu'est-ce que X ? », le modèle recherche la phrase qui relie directement X à sa signification.
En pratique : commencez vos articles par une définition directe du sujet. Pas d'introduction qui tourne autour du pot, pas de mise en contexte qui repousse la définition au troisième paragraphe.
2. Une structure question-réponse
Le contenu cité contient deux fois plus de points d'interrogation que le contenu non cité. 78,4 % des citations liées à une question proviennent de titres (balises H2 ou H3). L'IA traite votre titre de section comme une question d'utilisateur, et le paragraphe qui suit comme la réponse générée.
Cette mécanique porte un nom dans l'étude : l'« entity echoing » (l'écho d'entité). Si votre H2 pose la question « Qu'est-ce que le GEO ? » et que votre premier paragraphe commence par « Le GEO est… », vous créez une continuité sémantique que l'IA valorise fortement.
3. Une densité d'entités nommées élevée
Un texte standard en anglais contient entre 5 et 8 % de noms propres (marques, outils, personnes, lieux). Les contenus les plus cités dans l'étude atteignent 20,6 % de densité en entités nommées. Une entité nommée, c'est tout simplement un nom propre qui ancre le texte dans la réalité : ChatGPT, Gemini, Perplexity, HubSpot, Google, Kevin Indig...
L'explication tient à la logique probabiliste des LLM : une phrase vague comme « il existe de bons outils pour cette tâche » génère de l'incertitude. Une phrase qui cite « HubSpot, Salesforce ou Pipedrive » est vérifiable, précise, et réduit l'ambiguïté pour le modèle. Conclusion pratique : citez des noms, des outils, des personnes, des études. N'ayez pas peur de mentionner vos concurrents ou d'autres acteurs du secteur.
4. Un ton équilibré (ni trop sec, ni trop subjectif)
L'étude mesure ce qu'on appelle le score de subjectivité, un indicateur utilisé en traitement automatique du langage naturel qui va de 0 (texte purement factuel, style encyclopédie) à 1 (texte entièrement subjectif, style critique d'humeur). Les passages cités se concentrent autour d'un score de 0,47 : ni le texte Wikipedia ultra-factuel, ni l'opinion personnelle déchaînée.
Le ton idéal ressemble à celui d'un analyste ou d'un journaliste de presse économique : vous énoncez un fait, puis vous en tirez une interprétation. Exemple : « ChatGPT cite 44 % de son contenu dans le premier tiers des articles (fait). Cela signifie que placer vos conclusions en introduction n'est plus une option, c'est une nécessité stratégique (interprétation). »
5. Une écriture claire et accessible
L'étude utilise le score de Flesch-Kincaid, un indicateur qui mesure la lisibilité d'un texte en fonction de la longueur des phrases et des mots (plus le score est élevé, plus le texte est difficile à lire). Les contenus cités obtiennent un score de 16 (niveau universitaire), contre 19,1 pour les contenus non cités (niveau doctoral). Autrement dit, les phrases longues et le jargon technique dense nuisent à la citabilité. Une structure sujet-verbe-complément courte est plus facile à extraire pour le modèle.
Cela ne signifie pas qu'il faut simplifier à l'extrême. Il s'agit d'éviter les constructions alambiquées, non de supprimer la profondeur analytique.
Ce que ça change concrètement dans votre façon d'écrire
Ces cinq caractéristiques, combinées à la logique du ski ramp, dessinent une nouvelle façon d'aborder la rédaction pour le GEO. Ce n'est pas une révolution totale, mais un rééquilibrage significatif par rapport aux habitudes du SEO classique.
- Abandonnez les introductions qui « réchauffent » le lecteur : les longues mises en contexte qui repoussent la substance à la fin de l'intro sont pénalisantes pour la citabilité. Votre définition principale et votre conclusion essentielle doivent apparaître dans les deux à trois premiers paragraphes.
- Reformulez vos titres H2 en questions : au lieu de « Les avantages du marketing de contenu », préférez « Pourquoi le marketing de contenu génère du trafic ? ». Ce changement syntaxique améliore directement la probabilité que votre section soit traitée comme une réponse par le modèle.
- Citez des entités dès l'introduction : marques, outils, personnes, études, organisations. Ne restez pas dans le général. Plus votre introduction est ancrée dans des noms propres vérifiables, plus elle sera citée.
- Soignez votre section de conclusion : même si le pied-de-page est ignoré, une vraie section « Conclusion » ou « En résumé » juste avant capte encore 24 % des citations. C'est un espace précieux à ne pas négliger.
- Adoptez le ton « analyste » plutôt que le ton « guide ultime » : le style narratif long, qui retient la conclusion pour la fin, est structurellement désavantagé par rapport à un contenu structuré comme un briefing.
Les limites à garder en tête
Malgré la robustesse de l'étude, quelques précautions s'imposent avant d'en appliquer mécaniquement les conclusions.
D'abord, l'étude porte exclusivement sur ChatGPT. D'autres modèles comme Claude d'Anthropic, Gemini de Google ou Perplexity ont des architectures et des politiques de citation différentes. Les patterns observés sont vraisemblablement similaires — ces modèles partagent des bases d'entraînement communes — mais rien ne garantit que le ski ramp s'applique de façon identique à tous les LLM.
Ensuite, optimiser uniquement pour être cité ne suffit pas. Une citation dans une réponse ChatGPT n'a de valeur que si elle amène des visiteurs sur votre site, renforce votre autorité ou génère des opportunités commerciales. La mesure du retour sur investissement GEO reste complexe et nécessite des outils d'analyse dédiés.
Enfin, une mise en garde structurelle : adapter tous ses contenus à un format « briefing » au détriment du style narratif peut nuire à l'expérience utilisateur humaine. Le GEO et le SEO classique ne doivent pas s'opposer, mais se compléter. Un article bien structuré, avec une introduction dense et des titres en forme de questions, reste excellent pour le référencement Google tout en étant optimisé pour les IA.
Conclusion : la « taxe de clarté » que le GEO impose aux rédacteurs
Kevin Indig résume bien l'enjeu avec la notion de « taxe de clarté » : pour être visible dans les réponses des IA, vous devez désormais payer un coût éditorial supplémentaire. Ce coût, c'est de placer vos définitions, vos entités nommées et vos conclusions essentielles dès le début de vos contenus — et non les garder en récompense pour les lecteurs qui arrivent à la fin.
Ce n'est pas une mauvaise nouvelle. En réalité, les lecteurs humains et les IA partagent la même impatience : les uns comme les autres scannent un article pour en extraire l'essentiel rapidement. En écrivant pour la citabilité IA, vous écrivez aussi pour un lecteur pressé qui a peu de temps.
La véritable révolution n'est pas dans la technique, mais dans la mentalité : passer du mode « guide ultime » au mode « briefing analytique ». Conclusion d'abord, contexte ensuite. Entités nommées dès l'introduction. Titres posés comme des questions. Ton factuel mais interprété.
Les marques et les sites qui intégreront ces pratiques en 2026 prendront une avance concrète sur leur visibilité dans les réponses de ChatGPT, Claude, Gemini et Perplexity. Ceux qui continueront à rédiger des guides narratifs de 4 000 mots avec la définition à la section 7 seront tout simplement moins cités — indépendamment de la qualité intrinsèque de leur contenu.
Vous souhaitez auditer vos contenus existants à l'aune de ces nouvelles règles GEO ? Contactez notre équipe pour un accompagnement sur mesure.Sources et références
- Kevin Indig – The science of how AI pays attention (Growth Memo, février 2026)
- Search Engine Land – 44% of ChatGPT citations come from the first third of content: Study
Questions fréquentes sur les citations de ChatGPT
Pourquoi ChatGPT cite-t-il plus le début des articles ?
Les LLM ont été entraînés sur des millions d'articles de presse et de publications académiques qui suivent la structure « BLUF » (Bottom Line Up Front, ou conclusion en tête). Le modèle a appris que l'information la plus importante se trouve généralement en début de texte. Il établit son cadre de compréhension rapidement, puis interprète le reste à travers ce prisme.
Qu'est-ce qu'une entité nommée et pourquoi est-elle importante pour le GEO ?
Une entité nommée est un nom propre qui ancre un texte dans la réalité : une marque (ChatGPT, Google), un outil (HubSpot), une personne (Kevin Indig), une organisation. Les LLM préfèrent les phrases qui contiennent ces noms car elles sont précises et vérifiables, contrairement aux formulations génériques. Les textes très cités atteignent 20,6 % de densité en entités nommées, contre 5-8 % pour un texte standard.
Ces règles s'appliquent-elles aussi à Claude, Gemini et Perplexity ?
L'étude porte uniquement sur ChatGPT. Cependant, Claude, Gemini et Perplexity partagent des bases d'entraînement et des architectures similaires. Les patterns observés sont très vraisemblablement transposables, mais aucune étude équivalente n'a encore été publiée pour ces modèles. Il est prudent d'appliquer ces principes en les considérant comme des bonnes pratiques générales plutôt que comme des règles absolues validées pour tous les LLM.
Faut-il réécrire tous ses anciens articles pour le GEO ?
Pas nécessairement tous, mais les articles stratégiques (les plus trafiqués, les plus proches de vos mots-clés principaux) méritent un audit. Les ajustements prioritaires sont l'introduction (ajouter une définition directe et des entités nommées dès les 200 premiers mots), les titres H2 (les reformuler en questions), et la section de conclusion. Ces trois modifications peuvent significativement améliorer la citabilité sans réécriture complète.
Comment mesurer si mes contenus sont bien cités par les IA génératives ?
Plusieurs outils commencent à émerger pour mesurer la visibilité dans les réponses IA : Gauge (utilisé dans cette étude), Perplexity Analytics, et des outils de tracking des mentions IA. En attendant des solutions matures, vous pouvez effectuer des tests manuels réguliers en posant vos requêtes cibles à ChatGPT, Claude et Gemini, et en vérifiant si votre site est cité. Notre article sur les KPIs du GEO détaille les métriques à suivre.