La quantization des LLM : comment faire tourner une IA sur votre ordinateur ?
GPT, Mistral, Llama… Ces modèles pèsent des dizaines, voire des centaines de gigaoctets. Alors comment certains arrivent à les faire tourner sur un simple laptop ? La réponse tient en un mot : quantization. Cette technique permet de réduire drastiquement la taille d'un modèle en compressant la précision de ses données internes — sans sacrifier l'essentiel de ses performances. On vous explique tout.
-

- Dernière modification
27 mai 2026 - 9 minutes de lecture
📋 Sommaire ►
- Qu'est-ce que la quantization ?
- Pourquoi les LLM pèsent-ils si lourd ?
- Comment fonctionne la quantization en pratique ?
- Les différents niveaux de quantization
- Quels modèles peut-on faire tourner localement ?
- Les outils pour utiliser un LLM quantizé
- Quantization et GEO : ce que ça change pour votre stratégie
- Conclusion
- Sources et références
- Questions fréquentes sur la quantization des LLM
Qu'est-ce que la quantization ?
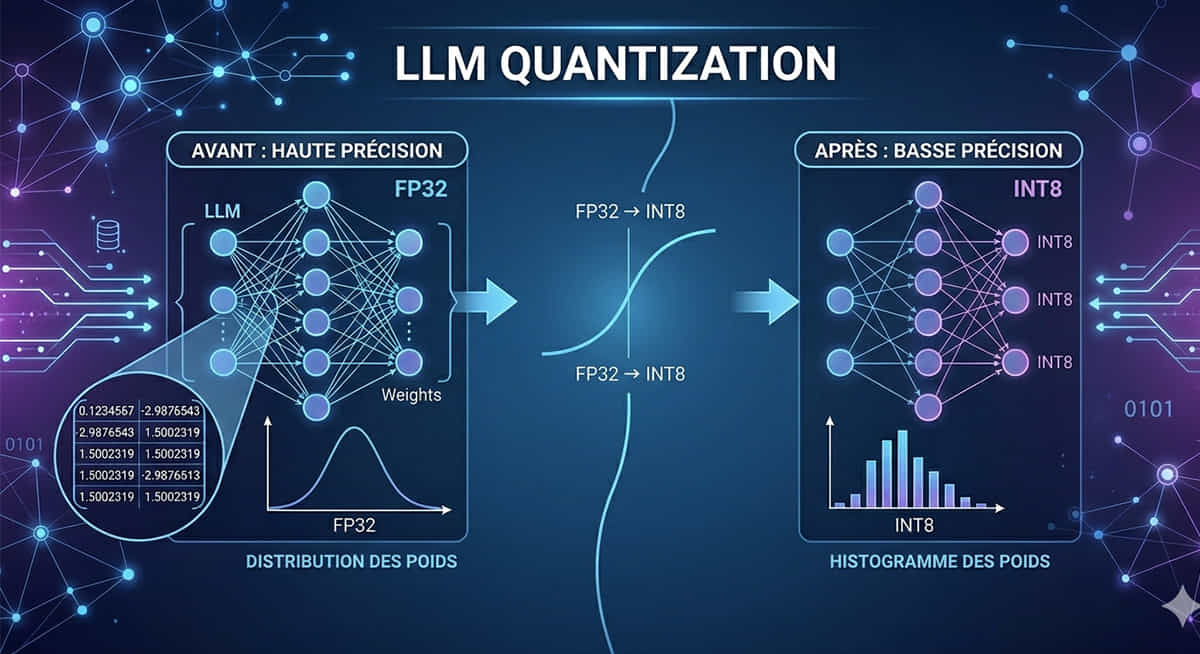
La quantization (ou quantification, en français) est une technique de compression appliquée aux modèles d'intelligence artificielle. Son principe est simple : réduire la précision des nombres utilisés pour stocker les données internes d'un modèle, appelées poids (ou weights en anglais — les valeurs numériques qui encodent tout ce qu'un LLM a appris).
Pour comprendre l'idée, voici une analogie. Imaginez que vous deviez noter la température extérieure. Vous pouvez l'écrire avec une précision extrême : 18,748291°C. Ou simplement noter : 19°C. Dans la grande majorité des cas, la seconde version suffit largement. La quantization applique ce même raisonnement aux milliards de nombres qui composent un LLM : on arrondit, on réduit la précision — et on gagne énormément de place.
Résultat concret : un modèle qui pesait 14 Go peut descendre à 4 ou 5 Go après quantization, tout en conservant des performances très proches de l'original. C'est ce qui rend possible l'exécution locale de LLM sur un ordinateur personnel, voire sur un téléphone haut de gamme.
Pourquoi les LLM pèsent-ils si lourd ?
Pour saisir l'enjeu de la quantization, il faut d'abord comprendre pourquoi les grands modèles de langage sont aussi volumineux.
Un LLM comme Llama 3 70B (le modèle open source de Meta avec 70 milliards de paramètres) stocke, pour chaque paramètre, un nombre en virgule flottante. Par défaut, ce nombre est encodé sur 32 bits (appelé FP32, pour Float Point 32). 70 milliards de paramètres × 32 bits = environ 280 Go de données. C'est bien plus que la RAM de n'importe quel ordinateur grand public.
Même en passant à une précision de 16 bits (FP16 ou BF16, les formats utilisés lors de l'entraînement de la plupart des modèles récents), on est encore autour de 140 Go. Inaccessible pour le commun des mortels.
C'est là qu'intervient la quantization : en réduisant encore plus la précision — 8 bits, 4 bits, voire 2 bits — on rend le modèle maniable. Un modèle 7B en 4 bits ne pèse plus que 3,5 à 4 Go. Un bon GPU grand public (ou même le GPU intégré d'un Mac M-series) peut le charger sans difficulté.
Comment fonctionne la quantization en pratique ?
Techniquement, la quantization consiste à mapper (c'est-à-dire faire correspondre, convertir) des valeurs continues à virgule flottante vers un ensemble discret de valeurs entières. Plus le nombre de bits est faible, moins il y a de valeurs possibles, et donc plus l'approximation est grossière.
Il existe deux grandes familles d'approches :
- La quantization post-entraînement (PTQ) : on prend un modèle déjà entraîné en pleine précision et on le compresse après coup. C'est l'approche la plus courante pour les modèles distribués sur des plateformes comme Hugging Face. Simple à mettre en œuvre, elle peut entraîner une légère perte de qualité.
- La quantization pendant l'entraînement (QAT, pour Quantization-Aware Training) : le modèle est entraîné en tenant compte dès le départ des contraintes de quantization. Le résultat est généralement de meilleure qualité, mais le processus est bien plus coûteux à mettre en place.
Les algorithmes les plus populaires aujourd'hui — comme GGUF (le format utilisé par llama.cpp), GPTQ ou AWQ — sont tous des variantes sophistiquées de quantization post-entraînement, optimisées pour minimiser la dégradation des performances.
La quantization n'est pas une nouveauté : on l'utilisait déjà en traitement du signal audio dans les années 1980. Ce qui est nouveau, c'est son application aux réseaux de neurones de plusieurs dizaines de milliards de paramètres — et les gains spectaculaires que ça permet.
Les différents niveaux de quantization
En pratique, les modèles quantizés sont distribués avec une indication du niveau de compression utilisé. Voici les principaux formats que vous rencontrerez :
- FP32 (32 bits) : la précision complète. Réservée à l'entraînement ou aux serveurs de recherche. Complètement inaccessible localement pour les grands modèles.
- FP16 / BF16 (16 bits) : le standard de déploiement sur GPU professionnel (A100, H100). Encore trop lourd pour une utilisation grand public sur la plupart des modèles de grande taille.
- Q8 (8 bits) : une première compression significative. La qualité reste très proche du modèle original. Nécessite encore une bonne quantité de RAM/VRAM — typiquement 8 à 10 Go pour un modèle 7B.
- Q4 (4 bits) : le meilleur compromis qualité/taille. C'est le format le plus utilisé pour les LLM locaux. Un modèle 7B ne pèse plus que 3,5 à 4,5 Go et tourne sur n'importe quel Mac M1/M2/M3 avec 8 Go de RAM unifiée, ou sur un PC avec une RTX 3060.
- Q2 / Q3 (2 à 3 bits) : compression maximale. La taille est minuscule, mais la dégradation de qualité devient perceptible. Réservé aux cas où la contrainte matérielle est très forte.
Une règle empirique souvent citée dans la communauté open source : Q4 est généralement suffisant pour la plupart des usages courants (génération de texte, résumé, Q&A simple). En dessous, les hallucinations augmentent et la cohérence du modèle se dégrade notablement.
Quels modèles peut-on faire tourner localement ?
La quantization a ouvert la porte à une véritable explosion des LLM locaux — c'est-à-dire des modèles qui tournent directement sur votre machine, sans envoyer vos données à un serveur tiers. Voici un panorama des modèles les plus populaires en 2026 :
Llama 3.3 (Meta)
La famille Llama de Meta est probablement la plus connue dans l'univers open source. Llama 3.3 70B en version Q4 pèse environ 40 Go et nécessite une machine bien équipée (Mac M2/M3 Max ou Pro avec 48 à 64 Go de RAM, ou un PC avec plusieurs GPU). Sa version 8B en Q4 (~4,5 Go) tourne sur n'importe quel Mac récent avec 8 Go de RAM, ou un PC grand public avec une RTX 3060.
Mistral et Mixtral (Mistral AI)
Le fleuron français de l'IA open source. Mistral 7B en Q4 est l'un des modèles les plus populaires pour une utilisation locale : à peine 4 Go, des performances remarquables pour sa taille, et une licence permissive. Mixtral 8x7B, une architecture MoE (Mixture of Experts — un modèle qui active uniquement une partie de ses paramètres à chaque requête, ce qui le rend plus efficace), est aussi disponible en version quantizée.
Gemma (Google)
Google a lancé sa famille Gemma spécifiquement pour les déploiements locaux. Gemma 2 9B en Q4 offre un excellent niveau de qualité pour un modèle de cette taille, avec une empreinte mémoire raisonnable (~5 Go).
Qwen (Alibaba)
Qwen 2.5 de la firme chinoise Alibaba propose des versions très compétitives en quantization. Qwen 2.5 7B en Q4 est particulièrement apprécié pour ses capacités en code et en raisonnement, à un coût mémoire très faible.
Phi-4 (Microsoft)
La famille Phi de Microsoft mise sur une approche différente : des modèles petits (3,8B à 14B paramètres) mais entraînés sur des données de très haute qualité. Phi-4 Mini en Q4 tourne sur un téléphone haut de gamme et montre qu'il est possible d'obtenir des réponses cohérentes avec très peu de ressources.
En bref : en 2026, un ordinateur grand public suffit pour faire tourner un LLM de qualité acceptable. Ce qui était réservé aux data centers il y a trois ans est désormais accessible sur votre bureau — ou dans votre poche.
Les outils pour utiliser un LLM quantizé
Avoir un modèle quantizé ne suffit pas : encore faut-il un logiciel pour l'exécuter. Voici les principaux outils accessibles, y compris pour des profils non techniques :
Ollama
Ollama est sans doute l'outil le plus simple pour débuter. Une commande dans le terminal suffit pour télécharger et lancer un modèle. Il gère automatiquement les versions quantizées et s'intègre avec de nombreuses interfaces. Disponible sur Mac, Windows et Linux, et totalement gratuit.
LM Studio
LM Studio est une application avec une interface graphique complète (donc pas de ligne de commande nécessaire). Elle permet de parcourir les modèles disponibles sur Hugging Face, de les télécharger, de les lancer et d'y accéder via une interface similaire à ChatGPT. Idéal pour ceux qui veulent explorer les LLM locaux sans passer par un terminal.
llama.cpp
llama.cpp est la brique technique sur laquelle reposent la plupart des autres outils. Ce projet open source, initialement créé par Georgi Gerganov, permet d'inférer (c'est-à-dire de faire tourner, d'utiliser) des LLM en format GGUF directement depuis le CPU ou le GPU, avec une optimisation poussée pour le matériel grand public. C'est la fondation sur laquelle Ollama s'appuie.
Jan
Jan est une alternative à LM Studio, également avec interface graphique, open source et conçue pour une expérience utilisateur fluide. Elle permet de passer d'un modèle à l'autre facilement et de configurer des paramètres avancés sans expertise technique.
Chez Digital-m, nous suivons de près l'évolution de ces outils pour accompagner les entreprises qui souhaitent déployer des LLM en local — notamment pour des raisons de confidentialité des données ou d'indépendance vis-à-vis des API cloud. Si vous êtes concerné, contactez-nous pour en discuter.
Quantization et GEO : ce que ça change pour votre stratégie
La montée en puissance des LLM locaux n'est pas sans conséquences pour votre stratégie de visibilité en ligne. Voici les points à garder en tête :
Des LLM partout, y compris hors connexion
Jusqu'à présent, les requêtes vers les LLM passaient par les serveurs d'OpenAI, Anthropic ou Google. Avec la démocratisation des modèles locaux, une partie croissante des interactions avec des IA se fera directement sur l'appareil de l'utilisateur, sans connexion externe. Ces modèles locaux sont entraînés sur des données qui ont une date de coupure — et votre contenu web peut y figurer, ou non, selon votre visibilité au moment de la collecte des données d'entraînement.
L'importance de la présence dans les corpus d'entraînement
Les modèles open source comme Llama, Mistral ou Qwen sont entraînés sur des corpus publics (Common Crawl, Wikipedia, GitHub…). Votre site web, s'il est bien indexé et régulièrement mis à jour, a davantage de chances d'être inclus dans les prochains cycles d'entraînement. C'est l'un des angles les moins évoqués du GEO (Generative Engine Optimization) : travailler sa présence pour les modèles futurs, pas seulement pour les requêtes en temps réel via RAG.
Des modèles moins puissants, des contenus qui doivent être plus clairs
Un LLM quantizé en Q4 est moins performant qu'un GPT-5.5 ou un Gemini 2.5 Pro sur des raisonnements complexes. Pour ces modèles à capacité réduite, un contenu clair, bien structuré et directement informatif sera mieux traité qu'un texte dense et ambigu. La lisibilité n'est pas qu'un enjeu SEO : c'est aussi un facteur de citabilité pour les IA moins puissantes.
C'est l'un des principes que nous appliquons systématiquement chez Digital-m dans nos audits GEO : tester la citabilité d'un contenu non seulement sur les grands modèles propriétaires, mais aussi sur des modèles locaux de taille intermédiaire — parce que ce sont eux que vos utilisateurs pourraient utiliser demain.
Conclusion
La quantization des LLM est une avancée technique majeure, souvent invisible du grand public, mais dont les effets sont profonds. Elle a transformé les LLM d'infrastructures réservées aux géants du cloud en outils accessibles à tous — sur votre ordinateur, sur votre téléphone, potentiellement demain sur votre montre connectée.
Comprendre ce mécanisme, c'est aussi mieux appréhender les limites des modèles avec lesquels vous travaillez au quotidien : un modèle quantizé en Q4 n'est pas le même outil qu'un GPT-5.5 en pleine précision. Les performances varient, et vos prompts, vos contenus, votre stratégie doivent en tenir compte.
Chez Digital-m, nous sommes convaincus que la prochaine frontière du GEO se jouera aussi sur ces modèles locaux. Si vous souhaitez être accompagné pour adapter votre stratégie de contenu à ce nouvel écosystème, contactez notre équipe ou découvrez notre formation GEO certifiée.
Et vous, avez-vous déjà essayé de faire tourner un LLM en local ? Dites-nous ce que vous en pensez en commentaire !Sources et références
- Hugging Face — Guide de la quantization
- llama.cpp — projet open source de Georgi Gerganov (GitHub)
- Ollama — site officiel
- LM Studio — site officiel
- GPTQ : Accurate Post-Training Quantization (arXiv)
- AWQ : Activation-aware Weight Quantization (arXiv)
- Meta — Llama 3 blog officiel
Questions fréquentes sur la quantization des LLM
C'est quoi la quantization d'un LLM en termes simples ?
La quantization consiste à réduire la précision des données internes d'un modèle d'IA (ses "poids") pour diminuer sa taille. Comme arrondir 18,748°C à 19°C : on perd un peu de précision, mais on gagne beaucoup de place. Cela permet de faire tourner des LLM sur des ordinateurs grand public.
Quel niveau de quantization choisir pour un LLM local ?
Pour la grande majorité des usages courants (génération de texte, résumé, questions-réponses), le format Q4 offre le meilleur compromis entre taille et qualité. Si votre machine a suffisamment de RAM, le Q8 sera encore plus proche de l'original. En dessous de Q4, la qualité se dégrade de façon perceptible.
Quel ordinateur faut-il pour faire tourner un LLM en local ?
Pour un modèle 7B en Q4 (format le plus courant), 8 Go de RAM suffisent sur un Mac avec puce M-series, ou un PC avec une carte graphique récente (RTX 3060 ou équivalent). Les Mac Apple Silicon (M1 à M4) sont particulièrement efficaces grâce à leur mémoire unifiée CPU/GPU. Pour les modèles plus grands (13B, 34B), il faudra davantage de RAM.
La quantization dégrade-t-elle vraiment les performances d'un LLM ?
Oui, mais de façon souvent imperceptible en usage courant pour un format Q4 ou Q8. Les études de benchmark montrent une perte de performance de 1 à 5 % par rapport au modèle original en pleine précision. La dégradation devient plus notable pour des tâches complexes (raisonnement long, mathématiques avancées) avec des formats très compressés (Q2 ou Q3).
Quels sont les avantages d'un LLM local par rapport à ChatGPT ou Gemini ?
Les principaux avantages sont la confidentialité des données (rien n'est envoyé à un serveur externe), l'absence de coût d'usage récurrent, la disponibilité hors connexion et la personnalisation complète du modèle. En contrepartie, les LLM locaux restent moins performants que les modèles cloud les plus puissants comme GPT-5.5 ou Gemini 2.5 Pro.