Réseaux de neurones convolutifs (CNN) : ce qu'ils font, et pourquoi ils sont différents des LLM
ChatGPT analyse du texte. Midjourney génère des images. Votre smartphone déverrouille votre visage en une fraction de seconde. Ces trois situations font appel à des types d'IA radicalement différents. Derrière la vision par ordinateur se cachent les réseaux de neurones convolutifs — les CNN — tandis que les LLM (grands modèles de langage) règnent sur le traitement du texte et du langage. Deux architectures, deux logiques, deux univers. Voici comment les distinguer clairement.
-

- Dernière modification
29 mai 2026 - 8 minutes de lecture
📋 Sommaire ►
- L'IA, un terme qui cache des réalités très différentes
- Qu'est-ce qu'un réseau de neurones convolutif (CNN) ?
- Comment fonctionne un CNN concrètement ?
- Qu'est-ce qu'un LLM, et comment ça fonctionne ?
- CNN vs LLM : les différences fondamentales
- Des usages bien distincts dans le monde réel
- Quand CNN et LLM travaillent ensemble : l'IA multimodale
- Ce que ça change pour votre stratégie digitale
- Conclusion
- Sources et références
- Questions fréquentes sur les CNN et les LLM
L'IA, un terme qui cache des réalités très différentes
Quand on parle d'intelligence artificielle, on amalgame souvent des technologies profondément différentes sous un même mot. L'IA qui reconnaît votre visage sur votre téléphone n'a rien à voir avec l'IA qui rédige un e-mail à votre place. La première est un réseau de neurones convolutif — un CNN, de l'anglais Convolutional Neural Network. La seconde est un LLM, un grand modèle de langage comme GPT-4o, Gemini 2.5 Pro ou Mistral Large.
Ces deux familles d'architectures ont été conçues pour résoudre des problèmes fondamentalement différents. Comprendre cette distinction, c'est poser les bases d'une vraie culture de l'IA — une culture qui devient indispensable pour tout professionnel du digital, du marketing ou de la communication en 2026.
Chez Digital-m, nous formons régulièrement des équipes marketing et des dirigeants à ces fondamentaux. Et invariablement, la confusion entre CNN et LLM revient comme l'une des plus fréquentes. Cet article est fait pour la dissiper une bonne fois pour toutes.
Qu'est-ce qu'un réseau de neurones convolutif (CNN) ?
Un réseau de neurones convolutif est un type d'architecture d'intelligence artificielle spécialement conçu pour analyser des données visuelles : images, vidéos, flux de caméras. Son nom vient d'une opération mathématique clé qu'il effectue — la convolution — mais inutile d'entrer dans les équations pour comprendre ce qui se passe réellement.
L'idée centrale est simple : un CNN apprend à détecter des motifs visuels, du plus simple au plus complexe. Dans les premières couches du réseau, il repère des éléments basiques — des bords, des contrastes, des lignes. Dans les couches suivantes, il combine ces éléments pour reconnaître des formes plus élaborées : un œil, une roue, une lettre. Et dans les couches profondes, il assemble tout ça pour identifier des objets complets : un visage, une voiture, un chien.
Le terme "convolution" désigne simplement une opération qui consiste à faire glisser un petit filtre sur une image pour en extraire des caractéristiques locales. Imaginez un détective qui examine une scène de crime avec une loupe, se déplaçant centimètre par centimètre pour ne rien manquer. C'est exactement ce que fait un CNN, mais à l'échelle des pixels.
En résumé : Un CNN est une IA entraînée à voir. Il décompose une image en niveaux de détail croissants pour en extraire du sens.
Une invention née de l'observation du cerveau visuel
Les CNN ont été inspirés par le fonctionnement du cortex visuel des mammifères. Dans les années 1960, les neuroscientifiques David Hubel et Torsten Wiesel ont découvert que les neurones du cerveau visuel s'activent de façon hiérarchique face à des stimuli visuels simples puis complexes. Cette observation a directement inspiré les architectures convolutives que Yann LeCun a formalisées dans les années 1980-1990.
En 2012, un tournant majeur : le réseau AlexNet, développé par Geoffrey Hinton et son équipe, remporte le concours de reconnaissance d'images ImageNet avec un écart de performance spectaculaire. L'ère des CNN modernes est lancée.
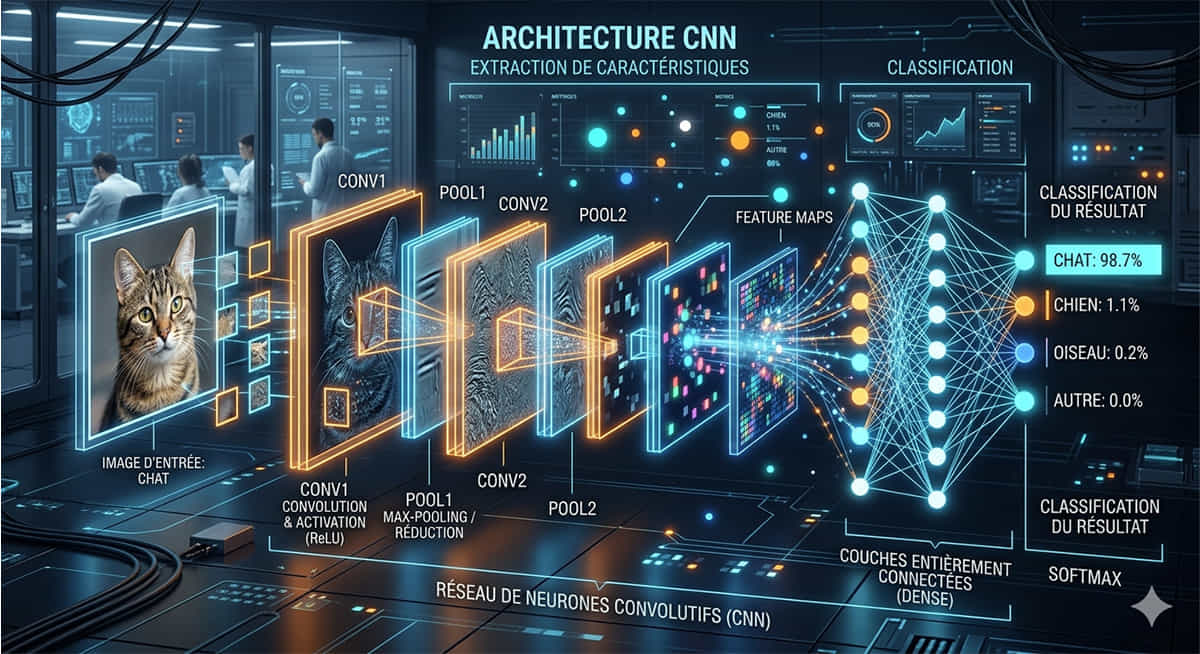
Comment fonctionne un CNN concrètement ?
Prenons un exemple concret. Vous souhaitez entraîner un CNN à reconnaître des photos de chats. Voici ce qui se passe :
- Couche d'entrée : l'image est transformée en une grille de valeurs numériques représentant les pixels et leurs couleurs (rouge, vert, bleu).
- Couches de convolution : des filtres glissent sur l'image pour détecter des motifs locaux — d'abord des contours, puis des textures (fourrure, oreilles pointues), puis des parties reconnaissables (museau, queue).
- Couches de pooling (sous-échantillonnage) : le réseau réduit la taille des données tout en conservant les informations essentielles. C'est ce qui rend le CNN efficace même face à des images de tailles variables ou légèrement déformées.
- Couches entièrement connectées : à partir des caractéristiques extraites, le réseau effectue la classification finale et répond : "Oui, c'est un chat" avec un niveau de confiance donné.
Ce processus est répété des millions de fois lors de l'entraînement, avec des milliers d'images étiquetées. Le réseau ajuste progressivement ses filtres pour minimiser ses erreurs. C'est ce qu'on appelle l'apprentissage par rétropropagation — le modèle corrige ses paramètres à chaque erreur, comme un enfant qui apprend à distinguer un chien d'un chat en voyant de nombreux exemples.
Qu'est-ce qu'un LLM, et comment ça fonctionne ?
Un LLM (Large Language Model — grand modèle de langage) est une architecture d'IA conçue pour traiter et générer du langage humain. Là où un CNN voit, un LLM lit, comprend et écrit. ChatGPT (OpenAI), Gemini (Google), Mistral (Mistral AI), Grok (xAI) ou encore Claude (Anthropic) sont tous des LLM.
La brique fondamentale d'un LLM est l'architecture Transformer, introduite en 2017 par des chercheurs de Google dans le papier fondateur "Attention is All You Need". Son principe central est le mécanisme d'attention : le modèle apprend à mettre en relation les mots d'une phrase entre eux, quelle que soit leur position, pour comprendre le sens global.
Concrètement, un LLM est entraîné sur des quantités astronomiques de texte — des milliards de pages web, de livres, d'articles scientifiques. Il apprend ainsi à prédire le mot (ou plus précisément le "token", un fragment de mot) qui devrait suivre dans une séquence donnée. Ce mécanisme de prédiction, répété à très grande échelle, fait émerger des capacités remarquables : raisonnement, synthèse, traduction, génération de code.
En résumé : Un LLM est une IA entraînée à comprendre et produire du langage. Il traite des séquences de texte en analysant les relations entre les mots à très grande échelle.
Ce que font vraiment les tokens
Un token n'est pas exactement un mot : c'est une unité de texte qui peut être un mot entier, un morceau de mot, ou même un signe de ponctuation. Le mot "intelligence" pourrait être découpé en "intel" + "ligence" selon le tokeniseur utilisé. Les LLM ne lisent pas des phrases — ils traitent des flux de tokens, dont ils calculent en permanence les relations statistiques. C'est ce qui leur permet de produire du texte cohérent, mais aussi de "confabuler" — c'est-à-dire d'inventer des informations plausibles mais fausses.
CNN vs LLM : les différences fondamentales
Maintenant que les deux architectures sont posées, voici comment les différencier sur les points qui comptent vraiment.
La nature des données traitées
C'est la différence la plus radicale. Un CNN traite des données spatiales — des pixels organisés en grille, où la position relative de chaque élément a une importance cruciale. Un LLM traite des données séquentielles — des tokens organisés dans le temps, où l'ordre et les relations entre éléments éloignés sont essentiels.
On ne fait pas lire un roman à un CNN, et on ne fait pas reconnaître un visage à un LLM (du moins, pas directement).
Le mécanisme d'apprentissage central
Le CNN utilise des filtres convolutifs qui glissent sur une image pour détecter des motifs locaux. Sa force réside dans ce qu'on appelle l'invariance par translation : même si un chat est dans le coin gauche ou au centre de l'image, le CNN le reconnaît.
Le LLM utilise un mécanisme d'attention qui calcule, pour chaque token, son degré de relation avec tous les autres tokens de la séquence. Cette capacité à établir des liens à longue distance est ce qui permet à un LLM de comprendre des textes complexes et des raisonnements en plusieurs étapes.
La taille et le coût d'entraînement
Un CNN performant peut être entraîné en quelques heures sur un seul GPU pour des tâches de classification standard. Les LLM modernes comme GPT-4 ou Gemini 2.5 Pro nécessitent des milliers de GPU pendant des semaines, pour un coût d'entraînement estimé entre 50 et 100 millions d'euros pour les plus grands modèles. Ce gouffre de ressources explique pourquoi les LLM sont dominés par quelques acteurs bien financés — OpenAI, Google, Anthropic, Meta, Mistral.
Les forces et les limites de chacun
Le CNN excelle là où les données sont visuelles et localement structurées. Il est rapide, léger, et peut être déployé sur des appareils embarqués (smartphones, caméras de surveillance, systèmes industriels). Ses limites apparaissent dès qu'on lui demande de gérer du contexte temporel long ou du raisonnement abstrait.
Le LLM excelle dans tout ce qui touche au langage : compréhension, génération, traduction, raisonnement, code. Ses limites sont le coût de fonctionnement, la tendance aux confabulations, et l'incapacité à traiter efficacement des données purement visuelles sans extension multimodale.
Des usages bien distincts dans le monde réel
Pour ancrer tout ça dans des cas concrets, voici comment CNN et LLM se partagent les grandes applications de l'IA en 2026.
Les domaines d'excellence des CNN
- Reconnaissance faciale : votre smartphone déverrouille votre visage grâce à un CNN. Les systèmes de contrôle d'accès dans les aéroports fonctionnent sur le même principe. Des architectures comme FaceNet ou ArcFace ont atteint des précisions supérieures à celle de l'œil humain sur certains jeux de données.
- Diagnostic médical par imagerie : les CNN analysent des radios, IRM et scanners pour détecter des tumeurs, des fractures ou des pathologies rétiniennes. Des études publiées dans Nature Medicine montrent que certains CNN surpassent des radiologues experts sur des tâches spécifiques de classification.
- Conduite autonome : les systèmes de perception des voitures autonomes (Tesla, Waymo) s'appuient massivement sur des CNN pour identifier en temps réel les piétons, panneaux de signalisation, autres véhicules et obstacles.
- Contrôle qualité industriel : des CNN inspectent des milliers de pièces à la seconde sur des lignes de production pour détecter des défauts invisibles à l'œil nu — une application qui remplace avantageusement les contrôleurs humains sur des tâches répétitives.
- Modération de contenu : Facebook, Instagram et YouTube utilisent des CNN pour détecter automatiquement les images inappropriées (nudité, violence) avant même qu'elles ne soient vues par un modérateur humain.
Les domaines d'excellence des LLM
- Assistants conversationnels : ChatGPT, Gemini, Claude, Mistral, Grok — tous ces outils que vous utilisez au quotidien pour rédiger, analyser, coder ou brainstormer sont des LLM.
- Génération et analyse de code : GitHub Copilot, Cursor ou encore Claude Code permettent à des développeurs de générer des fonctions entières, de détecter des bugs ou d'expliquer du code existant.
- Moteurs de recherche génératifs : Perplexity, Google AI Overviews, SearchGPT — ces nouveaux moteurs synthétisent l'information directement dans la réponse plutôt que de lister des liens.
- Traduction et localisation : DeepL et les fonctions de traduction intégrées dans les navigateurs s'appuient sur des architectures dérivées des Transformers.
- Résumé et analyse documentaire : analyser un contrat de 200 pages, extraire les clauses clés d'un appel d'offres ou synthétiser une étude de marché — autant de tâches où les LLM excellent.
Quand CNN et LLM travaillent ensemble : l'IA multimodale
La frontière entre les deux architectures s'est considérablement brouillée depuis 2023 avec l'essor de l'IA multimodale — des modèles capables de traiter simultanément du texte et des images.
Des modèles comme GPT-4o (OpenAI), Gemini 2.5 Pro (Google) ou Claude 3.7 Sonnet (Anthropic) peuvent analyser une image et en décrire le contenu, lire un graphique, interpréter une photo de document, ou encore générer du code à partir d'une capture d'écran d'interface. Ces systèmes combinent en réalité les deux approches : un encodeur visuel (souvent dérivé des CNN ou d'architectures comme ViT — Vision Transformer, c'est-à-dire un modèle qui applique le mécanisme d'attention des LLM aux images) prend en charge l'image, tandis que la partie LLM gère le raisonnement et la génération de texte.
L'IA multimodale, c'est la fusion des deux mondes : la capacité à voir des CNN, combinée à la capacité à comprendre et raisonner des LLM.
DALL-E (OpenAI), Midjourney ou Stable Diffusion font l'inverse : à partir d'une description textuelle traitée par un LLM, ils génèrent une image en s'appuyant sur des modèles de diffusion. Ces systèmes sont un excellent exemple de la complémentarité des deux architectures.
Ce que ça change pour votre stratégie digitale
Comprendre la distinction CNN / LLM n'est pas un exercice purement académique. Elle a des implications concrètes pour tout professionnel du digital.
Pour le contenu et le GEO
Les LLM sont au cœur du GEO (Generative Engine Optimization — l'art d'optimiser son contenu pour être cité par les intelligences artificielles génératives). ChatGPT, Gemini, Perplexity et consorts sont tous des LLM. Ce sont eux qui décident si votre contenu mérite d'être cité dans leurs réponses. Les stratégies GEO que développe Digital-m — structuration des contenus, densité sémantique, clarté des définitions dès le début des articles — ciblent directement ces architectures.
En revanche, quand vous optimisez les images de votre site (alt text, nommage des fichiers, légendes descriptives), vous parlez à la fois aux moteurs de recherche traditionnels et potentiellement aux systèmes de vision embarqués dans les outils d'IA multimodale.
Pour le SEO technique
Les CNN sont utilisés par Google et d'autres moteurs pour analyser les images et vidéos présentes sur vos pages. Google Lens, par exemple, s'appuie sur des architectures convolutives pour identifier des objets dans une image et en déduire l'intention de recherche. Optimiser vos images — pas seulement l'alt text, mais aussi la qualité, la pertinence visuelle et la cohérence avec le contenu textuel — devient un levier SEO à part entière.
Pour le choix de vos outils IA
Quand vous évaluez un outil d'IA pour votre entreprise, savoir si son cœur est un CNN ou un LLM vous aide à comprendre ce qu'il peut faire — et surtout ce qu'il ne fera jamais. Un outil de reconnaissance de reçus de frais ? CNN. Un assistant de rédaction ? LLM. Un outil d'analyse de tableaux de bord ? Probablement les deux, combinés dans une architecture multimodale.
Si vous souhaitez être accompagné pour auditer vos besoins IA et choisir les outils adaptés à votre activité, Digital-m propose des formations certifiées Qualiopi sur l'IA, le SEO et le GEO — accessibles à toute équipe, quel que soit le niveau technique de départ.
Conclusion
Les réseaux de neurones convolutifs et les LLM sont deux familles d'IA nées du même terreau — les réseaux de neurones artificiels — mais qui ont évolué vers des spécialisations radicalement différentes. Les CNN voient : ils analysent des pixels, détectent des formes, reconnaissent des visages. Les LLM lisent et raisonnent : ils comprennent le langage, génèrent du texte, synthétisent de l'information.
En 2026, les deux architectures convergent dans des modèles multimodaux qui combinent le meilleur des deux mondes. Mais connaître leurs différences de fond reste une base indispensable pour ne pas confondre les outils, les usages — et les attentes.
L'IA n'est pas un bloc monolithique. C'est un écosystème diversifié, où chaque architecture a été conçue pour résoudre un type de problème particulier. Plus tôt vous l'intégrez dans votre réflexion, plus vous serez en mesure de l'exploiter intelligemment — que ce soit pour votre contenu, votre site, votre équipe ou votre stratégie digitale. Et pour aller plus loin, Digital-m est là pour vous accompagner : contactez-nous pour un premier échange.
Et vous, saviez-vous que votre outil d'analyse d'images et votre assistant de rédaction reposaient sur des architectures aussi différentes ? Dites-le nous en commentaire !Sources et références
- Krizhevsky, Sutskever, Hinton — AlexNet (NeurIPS 2012)
- Vaswani et al. — Attention Is All You Need (Google Brain, 2017)
- Yann LeCun — LeNet et les origines des CNN
- Nature Medicine — IA et diagnostic médical par imagerie
- OpenAI — GPT-4 Technical Report
- Google DeepMind — Gemini
- Mistral AI — Architecture et modèles
- Dosovitskiy et al. — An Image is Worth 16x16 Words : ViT (2020)
Questions fréquentes sur les CNN et les LLM
Quelle est la différence entre un CNN et un LLM en termes simples ?
Un CNN (réseau de neurones convolutif) est une IA spécialisée dans l'analyse d'images et de vidéos : il détecte des formes, reconnaît des visages et identifie des objets visuels. Un LLM (grand modèle de langage) est une IA spécialisée dans le traitement du texte : il comprend et génère du langage humain. Le premier voit, le second lit et écrit.
ChatGPT utilise-t-il un CNN ?
Dans sa version de base, ChatGPT est un LLM pur — il traite du texte. Dans sa version multimodale (GPT-4o), il intègre un composant visuel capable d'analyser des images, qui s'appuie sur une architecture de vision distincte. C'est cette combinaison qui permet à ChatGPT d'analyser une photo ou de lire un document scanné.
Les CNN sont-ils encore utiles à l'ère des LLM multimodaux ?
Absolument. Les CNN restent les architectures de référence pour des applications temps réel nécessitant légèreté et rapidité : conduite autonome, contrôle qualité industriel, diagnostic médical par imagerie, systèmes embarqués. Leur efficacité sur des tâches visuelles spécifiques et leur faible coût de déploiement en font des outils incontournables, que les grands LLM multimodaux ne remplacent pas dans ces contextes.
Qu'est-ce qu'un Vision Transformer (ViT) ?
Un Vision Transformer (ViT) est une architecture qui applique le mécanisme d'attention des Transformers — la même brique que les LLM — aux images, en les découpant en petits blocs appelés "patches" (morceaux). Autrement dit, au lieu d'utiliser des filtres convolutifs comme un CNN, il analyse les relations entre ces blocs d'image. Il concurrence les CNN sur certaines tâches de vision, notamment quand de grandes quantités de données d'entraînement sont disponibles.
En tant que dirigeant ou marketeur, pourquoi est-il utile de comprendre cette différence ?
Comprendre la distinction CNN / LLM vous aide à mieux choisir vos outils IA, à formuler des briefs plus précis à vos équipes techniques, et à éviter les attentes irréalistes. Cela vous permet aussi de mieux appréhender les enjeux SEO liés aux images d'un côté, et l'optimisation GEO de votre contenu textuel de l'autre. C'est une culture de base qui fait gagner du temps et de la crédibilité.