Les embeddings : comment les LLM transforment les mots en mathématiques
Derrière chaque réponse de ChatGPT, Gemini, Mistral ou Grok se cache un mécanisme discret mais fondamental : les embeddings. Ces représentations mathématiques des mots sont la première étape par laquelle un modèle de langage "comprend" ce qu'on lui dit. Sans elles, aucun LLM ne fonctionnerait. Voici ce qu'elles sont, comment elles marchent — et pourquoi elles concernent directement votre stratégie de contenu.
-

- Dernière modification
4 juin 2026 - 8 minutes de lecture
📋 Sommaire ►
- Qu'est-ce qu'un embedding ?
- Comment un mot devient un vecteur
- L'espace vectoriel : la géographie secrète du langage
- Des mots aux phrases : les embeddings contextuels
- Embeddings et architecture transformer : le lien avec les LLM
- Les embeddings en dehors des LLM : moteurs de recherche et RAG
- Ce que les embeddings révèlent sur le fonctionnement des LLM
- Embeddings et GEO : ce que votre contenu signifie pour une IA
- Conclusion
- Sources et références
- Questions fréquentes sur les embeddings
Qu'est-ce qu'un embedding ?
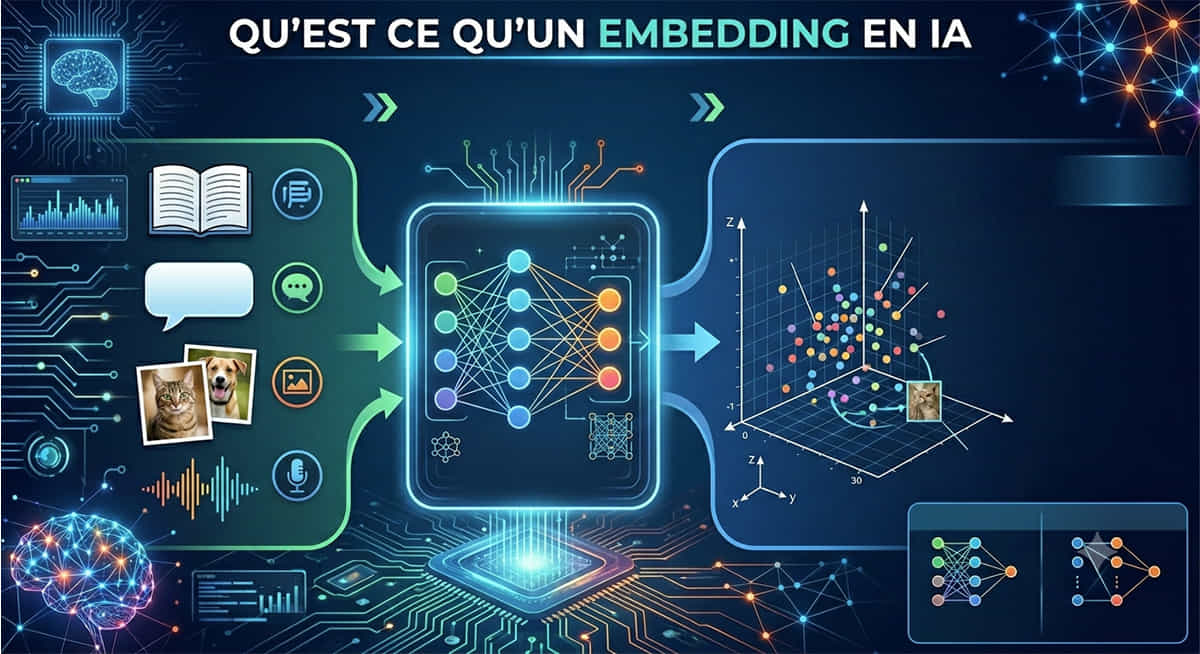
Pour un ordinateur, les mots n'existent pas. Il ne comprend que des nombres. Alors, comment un modèle comme GPT-5, Gemini ou Mistral peut-il lire une phrase, en saisir le sens, et produire une réponse cohérente ? La réponse tient en un seul mot : embedding.
Un embedding (en français : "plongement lexical") est la transformation d'un mot, d'une phrase ou d'un document en une liste de nombres — un vecteur mathématique. Ce vecteur encode le "sens" de l'élément dans un espace à plusieurs centaines, voire milliers de dimensions. C'est la façon dont un LLM représente et manipule le langage en interne.
L'idée n'est pas nouvelle : des chercheurs travaillent sur ces représentations depuis les années 2000, mais c'est le modèle Word2Vec, publié par Google en 2013, qui a véritablement popularisé le concept. Depuis, les embeddings sont devenus un composant central de tous les systèmes de traitement du langage naturel, des moteurs de recherche aux LLM les plus avancés de 2026.
Comment un mot devient un vecteur
Prenons un exemple concret. Avant d'être traité par un LLM, le mot "chat" ne sera pas transmis comme une chaîne de caractères. Il passera par deux étapes distinctes.
Étape 1 : la tokenisation
Le texte est d'abord découpé en tokens — des sous-unités de langage qui peuvent être des mots entiers, des syllabes, ou même des caractères isolés. Le mot "tokenisation" pourrait par exemple être découpé en ["token", "isation"]. Chaque token reçoit alors un identifiant numérique unique dans le vocabulaire du modèle.
Étape 2 : la projection dans l'espace vectoriel
Cet identifiant numérique est ensuite converti en vecteur d'embedding : une liste de nombres en virgule flottante. Pour les grands modèles actuels, ce vecteur peut avoir entre 768 et 4 096 dimensions, selon l'architecture. Chaque dimension encode une caractéristique abstraite du mot — non pas des traits lisibles par un humain, mais des patterns statistiques appris lors de l'entraînement sur des milliards de textes.
C'est lors de l'entraînement que le modèle apprend à attribuer des valeurs cohérentes à ces dimensions. Deux mots qui apparaissent souvent dans des contextes similaires finiront par avoir des vecteurs proches. C'est ainsi que la machine "apprend" le sens des mots — non pas par définition, mais par usage.
L'espace vectoriel : la géographie secrète du langage
La propriété la plus fascinante des embeddings est ce qu'ils révèlent sur la structure du langage une fois placés dans un espace mathématique commun.
Des mots proches qui se ressemblent
Dans cet espace vectoriel, la distance entre deux vecteurs reflète la proximité sémantique des mots correspondants. Les mots "roi", "reine" et "monarque" se retrouveront géométriquement proches. "Chien" et "chat" seront plus proches l'un de l'autre que "chien" et "turbine". Ce n'est pas programmé explicitement : c'est une propriété émergente de l'entraînement sur de grandes quantités de texte.
L'arithmétique du sens
Un exemple célèbre illustre la puissance de ce mécanisme. Avec des embeddings bien entraînés, on peut effectuer l'opération suivante :
vecteur("roi") − vecteur("homme") + vecteur("femme") ≈ vecteur("reine")
Ce résultat n'est pas magique. Il signifie que les embeddings ont capturé, dans leurs dimensions, des relations sémantiques régulières : la relation entre "roi" et "homme" est la même qu'entre "reine" et "femme". Le modèle a appris la structure relationnelle du langage de manière purement mathématique, sans qu'on lui ait jamais expliqué ce qu'est un roi ou une reine.
Des clusters naturels
Si l'on visualise des embeddings en 2D ou 3D (via des techniques de réduction de dimensions comme t-SNE ou UMAP), on observe des clusters thématiques naturels : les noms de pays se regroupent, les verbes d'action se rapprochent, les termes médicaux forment un nuage cohérent. La géographie de cet espace reflète, en quelque sorte, la géographie du sens humain.
Des mots aux phrases : les embeddings contextuels
Les premiers modèles d'embeddings comme Word2Vec avaient une limitation majeure : un mot avait un seul vecteur fixe, quel que soit son contexte. Le mot "banque" avait la même représentation qu'il s'agisse d'une banque financière ou de la berge d'un fleuve.
La révolution des embeddings contextuels
Les architectures modernes — à commencer par BERT (Google, 2018) puis les Transformers qui alimentent les LLM actuels — ont résolu ce problème avec les embeddings contextuels. Dans ces modèles, le vecteur d'un mot n'est pas fixe : il est recalculé en fonction des autres mots de la phrase.
Dans la phrase "Je vais à la banque retirer de l'argent", le vecteur de "banque" intégrera le contexte financier. Dans "Il s'est assis sur la berge de la banque", le même mot aura un vecteur différent, orienté vers le sens géographique. Cette contextualisation est ce qui permet aux LLM de lever les ambiguïtés du langage naturel.
Des embeddings de phrase et de document
Au-delà des mots, il est possible de créer des embeddings pour des phrases, des paragraphes ou des documents entiers. Un embedding de phrase encode le sens global de la phrase dans un seul vecteur. C'est cette capacité qui est exploitée dans de nombreuses applications concrètes : moteurs de recherche sémantique, systèmes de recommandation, détection de contenus similaires.
Embeddings et architecture transformer : le lien avec les LLM
Pour comprendre comment les embeddings s'intègrent dans un LLM comme GPT-5, Gemini ou Llama, il faut remonter à l'architecture Transformer publiée par Google en 2017 dans le papier fondateur "Attention Is All You Need".
La couche d'embedding : première étape du traitement
Dans un Transformer, les embeddings constituent la toute première couche du modèle. Avant tout traitement, chaque token du texte d'entrée est converti en vecteur d'embedding. Ce vecteur est ensuite enrichi d'un encodage positionnel — une information supplémentaire qui dit au modèle où le token se trouve dans la séquence. Car contrairement à un humain qui lit de gauche à droite, un Transformer traite tous les tokens simultanément et a besoin d'informations sur leur ordre.
Le mécanisme d'attention : quand les embeddings interagissent
Une fois les embeddings calculés, le mécanisme d'attention multi-têtes (multi-head attention) entre en jeu. C'est là que chaque token "regarde" tous les autres tokens de la séquence et calcule à quel point ils sont pertinents pour sa propre représentation. Ce mécanisme affine les embeddings au fil des couches du modèle : un token commence avec un vecteur générique et se retrouve, en sortie du dernier Transformer, avec un vecteur fortement contextualisé.
Plus un modèle a de couches (GPT-4 en a 96, Llama 3 70B en a 80), plus les embeddings sont raffinés et capables de capter des relations sémantiques subtiles.
Les embeddings de sortie
En fin de traitement, le modèle utilise les embeddings contextualisés pour prédire le prochain token le plus probable. C'est le cœur de la génération de texte : le LLM ne "choisit" pas sa réponse d'un coup, il la construit token par token, en recalculant à chaque étape quel vecteur est le plus cohérent avec ce qui précède.
Les embeddings en dehors des LLM : moteurs de recherche et RAG
Les embeddings ne servent pas seulement à l'intérieur des LLM. Ils sont également au cœur de plusieurs technologies qui façonnent le web en 2026.
La recherche sémantique
Un moteur de recherche classique fonctionne par mots-clés : il cherche des pages qui contiennent exactement les termes tapés par l'utilisateur. Un moteur de recherche sémantique va plus loin : il convertit la requête de l'utilisateur en vecteur d'embedding et cherche les documents dont les vecteurs sont les plus proches — c'est-à-dire les plus proches sémantiquement, même si les mots exacts ne correspondent pas.
Concrètement, cela signifie qu'une recherche pour "voiture électrique abordable" peut retourner des résultats mentionnant "véhicule zéro émission à petit prix", sans qu'aucun des mots exacts ne corresponde. Google, Bing et Perplexity utilisent tous des formes de recherche sémantique basée sur des embeddings.
Le RAG : quand les embeddings connectent les LLM au monde réel
Le RAG (Retrieval-Augmented Generation — en français : génération augmentée par récupération) est une technique qui permet à un LLM d'aller chercher des informations dans une base de données externe avant de répondre. C'est le mécanisme utilisé par Perplexity, SearchGPT ou les AI Overviews de Google.
Voici comment les embeddings interviennent dans ce processus :
- Indexation : tous les documents de la base (articles de blog, pages web, fichiers PDF…) sont convertis en vecteurs d'embedding et stockés dans une base de données vectorielle (comme Pinecone, Weaviate ou Chroma).
- Requête : quand l'utilisateur pose une question, celle-ci est également convertie en vecteur d'embedding.
- Recherche : le système trouve les documents dont les vecteurs sont les plus proches de celui de la requête — c'est-à-dire les plus pertinents sémantiquement.
- Génération : les documents récupérés sont injectés dans le contexte du LLM, qui s'en sert pour formuler une réponse précise et sourcée.
Pour les professionnels du marketing et du SEO, cette architecture a une implication directe : la pertinence de votre contenu n'est plus seulement une question de mots-clés. C'est la cohérence sémantique de votre texte dans son ensemble qui détermine si un LLM le retrouvera et le citera.
Ce que les embeddings révèlent sur le fonctionnement des LLM
Comprendre les embeddings aide à lever plusieurs malentendus fréquents sur ce que les LLM font — ou ne font pas.
Un LLM ne "comprend" pas comme un humain
Les embeddings sont des représentations statistiques, pas des représentations conceptuelles. Quand GPT-5 ou Gemini associe "médecin" et "hôpital", ce n'est pas parce qu'il a compris ce qu'est un médecin : c'est parce que ces deux mots apparaissent souvent ensemble dans le corpus d'entraînement. La cohérence apparente des réponses des LLM repose sur des patterns statistiques extrêmement riches — pas sur une compréhension du monde au sens humain du terme.
Les biais d'entraînement se reflètent dans les embeddings
Si le corpus d'entraînement contient des biais — des associations récurrentes entre certains groupes et certains attributs — ces biais se retrouvent encodés dans les embeddings. C'est l'une des raisons pour lesquelles les équipes d'Anthropic, d'OpenAI ou de Google DeepMind travaillent activement sur des techniques d'alignement comme le RLHF (Reinforcement Learning from Human Feedback) pour corriger ces déformations.
Pourquoi les LLM peuvent "halluciner"
Les hallucinations — le fait qu'un LLM génère des informations fausses avec assurance — sont en partie liées à la nature probabiliste des embeddings. Le modèle prédit le token le plus plausible dans l'espace vectoriel, pas le plus exact. Si deux contextes produisent des vecteurs similaires, le modèle peut confondre des informations qui semblent sémantiquement proches mais sont factuellement distinctes.
Chez Digital-m, nous formons régulièrement les équipes marketing à ces mécanismes dans le cadre de nos formations GEO certifiées Qualiopi. Comprendre pourquoi un LLM hallucine, c'est aussi comprendre comment structurer ses contenus pour minimiser ce risque — et maximiser les chances d'être cité correctement.
Embeddings et GEO : ce que votre contenu signifie pour une IA
Pour les professionnels du marketing digital, les embeddings ne sont pas qu'un sujet académique. Ils ont des implications très concrètes sur la façon dont les LLM perçoivent et citent votre contenu.
La cohérence sémantique, signal de qualité
Quand un LLM (ou un moteur de recherche sémantique comme Perplexity) évalue un article, il construit un embedding de l'ensemble du texte. Un article dont les paragraphes se contredisent, partent dans tous les sens ou utilisent un vocabulaire incohérent produira un vecteur "bruité", difficile à rapprocher d'une requête précise. À l'inverse, un article avec une structure sémantique claire — une idée principale bien développée, un vocabulaire cohérent, des sous-thèmes logiquement reliés — produira un vecteur propre, facilement récupérable par un système RAG.
Les champs sémantiques enrichissent les embeddings
Un contenu qui utilise les termes du domaine dans leur contexte naturel — synonymes, hypéronymes, termes associés — produit des embeddings plus riches et plus proches de ceux des requêtes des utilisateurs. C'est la logique derrière le conseil souvent répété en GEO : couvrir un sujet en profondeur plutôt qu'en surface. Ce n'est pas qu'une question de longueur — c'est une question de densité sémantique.
Les définitions et réponses directes facilitent la récupération
Les systèmes RAG cherchent des passages qui répondent directement à une question. Un article qui commence par poser clairement sa définition — "Un embedding est une représentation mathématique d'un mot sous forme de vecteur numérique" — produit un embedding de paragraphe immédiatement aligné avec les requêtes de type "qu'est-ce qu'un embedding". Cette pratique est l'une des bases du GEO (Generative Engine Optimization), la discipline qui vise à optimiser la visibilité d'un contenu dans les réponses des IA.
Sur Horizon GEO, le blog de Digital-m, nous avons documenté comment 44 % des citations de ChatGPT viennent du premier tiers des articles — une donnée directement liée à la façon dont les embeddings de début de document sont surreprésentés dans les systèmes de récupération RAG.
Le maillage interne renforce la cohérence sémantique globale
Les embeddings ne s'appliquent pas seulement au niveau d'un article isolé. Les systèmes RAG avancés peuvent prendre en compte l'ensemble d'un site web. Un maillage interne cohérent — des articles liés thématiquement entre eux — crée un "quartier sémantique" dans l'espace vectoriel, renforçant l'autorité thématique perçue par les LLM. C'est l'une des raisons pour lesquelles nous travaillons sur la structure du maillage interne spécifiquement orientée LLM dans nos audits GEO.
Conclusion
Les embeddings sont, avec la tokenisation et le mécanisme d'attention, l'un des trois piliers techniques qui expliquent le fonctionnement des LLM. Ils permettent à des modèles comme GPT-5, Gemini, Mistral ou Claude de "lire" le langage non pas comme une suite de caractères, mais comme un espace de sens structuré mathématiquement.
Comprendre les embeddings, c'est comprendre pourquoi un LLM associe certains mots, pourquoi il peut halluciner, et surtout pourquoi la structure sémantique de votre contenu est aussi importante que ses mots-clés exacts. À l'heure où les IA génératives deviennent des points d'entrée incontournables pour des millions d'utilisateurs, cette compréhension n'est plus réservée aux ingénieurs : elle est devenue un outil stratégique pour tout professionnel du digital.
Vous souhaitez savoir comment votre contenu est perçu sémantiquement par les LLM ? L'équipe de Digital-m propose des audits GEO qui analysent la cohérence sémantique de vos pages — et les moyens d'améliorer votre visibilité dans les réponses des intelligences artificielles.
Et vous, aviez-vous déjà entendu parler des embeddings avant de lire cet article ? Partagez en commentaire !Sources et références
- Mikolov et al. — Efficient Estimation of Word Representations in Vector Space (Word2Vec, 2013)
- Vaswani et al. — Attention Is All You Need (Architecture Transformer, 2017)
- Devlin et al. — BERT: Pre-training of Deep Bidirectional Transformers (2018)
- OpenAI — Guide des embeddings
- Hugging Face — Getting Started with Embeddings
- Pinecone — What are vector embeddings?
- Horizon GEO — 44 % des citations ChatGPT viennent du premier tiers de vos articles
Questions fréquentes sur les embeddings
C'est quoi un embedding en termes simples ?
Un embedding est la transformation d'un mot ou d'une phrase en une liste de nombres (un vecteur). Ce vecteur encode le "sens" du mot de façon mathématique, ce qui permet à un ordinateur de manipuler le langage comme s'il en comprenait la signification. Deux mots proches sémantiquement auront des vecteurs proches dans cet espace numérique.
Quelle est la différence entre token et embedding ?
Un token est l'unité de base dans laquelle un texte est découpé (mot, syllabe ou caractère). Un embedding est la représentation mathématique (vecteur numérique) de ce token. La tokenisation est l'étape de découpe ; l'embedding est l'étape de transformation en nombres. Les deux se succèdent dans le pipeline d'un LLM.
Pourquoi les embeddings sont-ils importants pour le SEO et le GEO ?
Les moteurs de recherche modernes et les systèmes RAG utilisés par les LLM comparent des embeddings pour retrouver les contenus pertinents. Un texte sémantiquement cohérent, qui couvre un sujet en profondeur avec un vocabulaire riche et précis, produit de meilleurs embeddings et sera plus facilement retrouvé et cité par les IA. La densité sémantique est donc un signal de qualité direct pour le GEO.
Qu'est-ce qu'une base de données vectorielle ?
Une base de données vectorielle (ou "vector database") est un système de stockage spécialement conçu pour enregistrer et interroger des embeddings. Plutôt que de chercher des correspondances exactes comme une base de données classique, elle recherche les vecteurs les plus proches d'une requête donnée — c'est-à-dire les documents les plus proches sémantiquement. Des outils comme Pinecone, Weaviate ou Chroma sont des exemples populaires, très utilisés dans les architectures RAG.
Tous les LLM utilisent-ils les mêmes embeddings ?
Non. Chaque LLM développe ses propres embeddings lors de son entraînement, selon l'architecture choisie, la taille du modèle et le corpus utilisé. GPT-5, Gemini, Mistral et Llama n'ont pas les mêmes représentations internes, même si elles capturent des structures sémantiques similaires. Il existe aussi des modèles d'embeddings spécialisés, indépendants des LLM génératifs, utilisés spécifiquement pour la recherche sémantique (comme text-embedding-3 d'OpenAI ou les modèles de la famille Sentence-BERT).