Qu'est-ce qu'un transformeur en IA ?
Plongez dans l'univers des transformeurs, l'architecture révolutionnaire au cœur des LLM comme GPT et Claude. Apprenez simplement comment ils fonctionnent, leurs avantages et applications en 2026 pour booster votre compréhension de l'IA – lisez notre guide complet !
-

- Dernière modification
29 janvier 2026 - 5 minutes de lecture
Saviez-vous que depuis 2017, une seule architecture d’intelligence artificielle a permis à des outils comme ChatGPT de rédiger des articles entiers ou de traduire des langues en temps réel ? C’est le transformeur, un pilier des grands modèles de langage (LLM) qui a transformé le paysage de l’IA. En janvier 2026, avec l’essor de modèles comme Gemini ou Grok, comprendre les transformers devient essentiel pour tout entrepreneur ou marketeur qui veut intégrer l’IA dans ses stratégies. Cet article décompose ce concept technique de manière accessible, sans jargon excessif. Nous explorerons ses origines, son fonctionnement étape par étape, et ses applications concrètes. À la fin, vous saurez pourquoi les transformeurs surpassent les anciennes méthodes et comment ils influencent les LLM d’aujourd’hui. Prêt à démystifier cette technologie qui traite des milliards de données en parallèle ? Let’s go !
Les origines des transformeurs
Les transformeurs n’ont pas toujours dominé l’IA. Avant leur apparition, les modèles reposaient sur des réseaux de neurones récurrents (RNN), comme les LSTM, qui traitaient les données mot par mot, de manière séquentielle. Cela posait des problèmes : pour des phrases longues, l’information du début se perdait, un phénomène appelé “évanescence du gradient”. En 2014, des mécanismes d’attention ont été ajoutés pour mieux capter les relations entre les mots, mais c’est en 2017 que tout change.
Une équipe de chercheurs chez Google publie l’article “Attention Is All You Need”, introduisant le transformeur. Cette architecture abandonne complètement les RNN au profit d’un système basé uniquement sur l’attention, permettant un traitement parallèle des données. Résultat ? Des entraînements plus rapides sur des datasets massifs, comme des milliards de pages web. En 2026, cette base sert à des LLM comme GPT-4 ou Claude 3, entraînés sur des téraoctets de texte pour générer des réponses naturelles.
Pourquoi ce nom ? “Transformer” évoque la transformation d’une séquence d’entrée (comme une phrase en anglais) en sortie (sa traduction en français), mais il s’applique bien au-delà du texte, à des images ou des vidéos.
L’architecture d’un transformeur expliquée simplement
Imaginez un transformeur comme une usine intelligente qui traite des données en lots, plutôt qu’une chaîne de montage linéaire. Son architecture se divise en deux parties principales : l’encoder (codeur) et le decoder (décodeur). Ensemble, ils convertissent une entrée en sortie, en capturant les relations entre éléments.
L’encoder : capturer le contexte
L’encoder est une pile de couches identiques (souvent 6 ou plus dans les modèles modernes). Il prend une séquence d’entrée, comme des mots tokenisés (divisés en unités basiques), et les transforme en représentations riches en contexte.
- Embeddings initiaux : Chaque mot est converti en vecteur numérique, capturant son sens sémantique.
- Encodage positionnel : Puisque le transformer ne traite pas séquentiellement, on ajoute des informations sur la position des mots via des formules sinus et cosinus. Cela crée des motifs uniques pour chaque place dans la phrase, évitant que “Le chat mange la souris” soit confondu avec “La souris mange le chat”. (ce qui arrive rarement, nan ?)
Chaque couche de l’encodeur inclut :
- Un mécanisme d’attention pour relier les mots entre eux.
- Un réseau feed-forward (deux couches linéaires avec une activation) pour affiner les représentations.
- Des connexions résiduelles et une normalisation pour stabiliser l’apprentissage.
À la sortie, l’encoder fournit une vue globale de la séquence, idéale pour des tâches comme la compréhension de texte dans BERT (modèle de langage développé par Google en 2018.)
Le decoder : générer la sortie
Le decoder fonctionne de manière similaire, mais avec un twist : il génère la sortie token par token, en s’appuyant sur l’encoder. Il inclut aussi une pile de couches, avec :
- Une attention masquée pour ne pas “voir” les tokens futurs (évite les tricheries pendant la génération).
- Une attention croisée qui lie le decoder à l’encoder.
- Le même réseau feed-forward.
Par exemple, dans une traduction, l’encoder analyse la phrase source, et le decoder produit la cible mot par mot. Dans les LLM comme GPT, on utilise souvent un decoder seul pour la génération autoregressive : le modèle prédit le mot suivant basé sur les précédents.
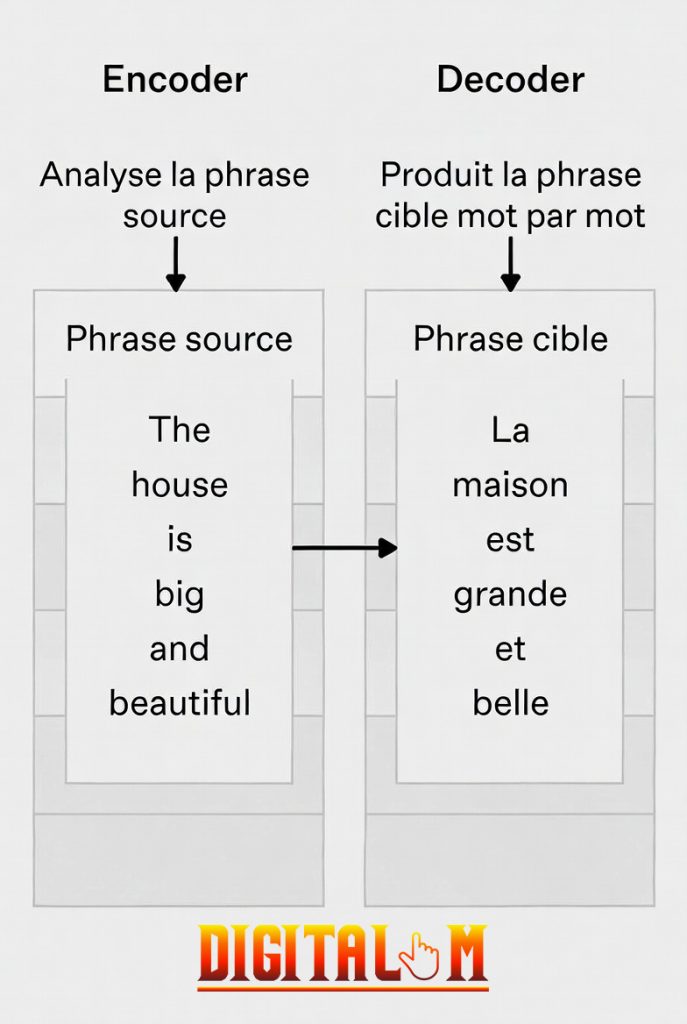
Dans le cas d’une traduction, voici comment fonctionnent le modèle Encoder-Decoder
Le cœur du transformeur : le mécanisme d’attention
C’est ici que la magie opère. L’attention permet au modèle de se concentrer sur les parties pertinentes d’une séquence, comme un humain qui relie des idées distantes dans un texte. Si vous deviez retenir qu’une chose à propos des transformeurs, c’est cette notion d’attention.
Comment fonctionne l’attention ?
Pour chaque mot (token), on crée trois vecteurs :
- Query (requête) : Ce que le token “cherche”.
- Key (clé) : Ce qui identifie les autres tokens.
- Value (valeur) : L’information à extraire.
On calcule des scores via un produit scalaire (query x key), normalisé pour éviter des explosions numériques (valeurs infinies), puis on applique une softmax pour obtenir des poids (probabilités). La sortie est une somme pondérée des valeurs. Exemple : Dans “Le chien court dans le parc”, “court” prête plus d’attention à “chien” qu’à “parc”.
Ces étapes permettent aux Transformeurs de capturer des dépendances à longue distance dans le texte, rendant les modèles très puissants pour des tâches comme la traduction ou la génération de texte.
Pour expliquer un peu plus “simplement”, l’attention va faire en sorte que le résultat soit compréhensible en sortie. Sans cela, on risquerait d’avoir des résultats incompréhensibles ou trop longs pour le commun des mortels.
Vous êtes paumés ? Non ? Alors, on continue ;).
L’attention multi-tête pour plus de finesse
Au lieu d’une seule attention, on en utilise plusieurs “têtes” en parallèle (souvent 8 ou 16). Chaque tête capture des relations différentes : une pour la grammaire, une pour le sens. Les résultats sont combinés, rendant le modèle plus robuste. Cela explique pourquoi les LLM comme Claude gèrent des contextes complexes sans perte d’information.
Contrairement aux RNN (les anciens modèles), l’attention permet un accès direct à tous les tokens, idéal pour des phrases longues. En 2026, avec des modèles entraînés sur des datasets de plus de 1 trillion de tokens, cela booste donc les performances de façon spectaculaire.
Applications des transformers dans les LLM
Les transformeurs ne se limitent pas à la théorie. Ils sont utilisés par des outils quotidiens :
- Génération de texte : GPT utilise un decoder pour créer des paragraphes cohérents, comme rédiger un email ou coder.
- Compréhension bidirectionnelle : BERT (basé sur encoder) analyse le contexte des deux côtés d’un mot pour des tâches comme la recherche sémantique.
- Multimodalité : Des variantes comme Vision Transformer (ViT) traitent des images, et Gemini intègre texte, images et vidéos.
- Exemples concrets : En marketing, un LLM comme Grok analyse des avis clients ; en traduction, Claude convertit des langues en temps réel avec une précision de 95 % sur des benchmarks comme BLEU.
En 2025, plus de 90 % des nouveaux LLM reposent sur des transformeurs, selon des rapports d’OpenAI et Anthropic.
Avantages et limites des transformers
Pourquoi les transformeurs dominent-ils dans le fonctionnement des LLM ?
- Parallélisation : Traitement simultané sur GPU, réduisant les temps d’entraînement de jours à heures.
- Gestion des dépendances longues : Pas de perte d’information sur des textes de milliers de mots.
- Scalabilité : Facile à agrandir, comme avec des milliards de paramètres dans GPT-4.
Mais ils ont des limites : ils consomment beaucoup d’énergie (un entraînement peut coûter des millions d’euros) et nécessitent des données massives. En 2026, des recherches se concentrent sur des versions plus efficaces, comme les transformeurs sparsifiés.
C’est également pour cela que des SLM (Small Language Model) se développent.
Les transformeurs représentent le fondement des LLM modernes, transformant des séquences de données en sorties intelligentes via l’attention et une architecture encoder-decoder. De leurs origines en 2017 à leurs applications dans GPT, Claude ou Gemini, ils ont démocratisé l’IA pour les entrepreneurs et le grand public. Si vous voulez intégrer ces technologies dans votre business, commencez par tester un LLM gratuit.
FAQ sur les transformeurs
Quelle est la différence entre un transformeur et un RNN ?
Un transformer traite les données en parallèle via l’attention, évitant les pertes d’information sur les longues séquences, contrairement aux RNN qui sont séquentiels et plus lents.
Pourquoi les transformeurs sont-ils essentiels pour les LLM ?
Ils permettent une compréhension contextuelle profonde, comme dans GPT pour générer du texte, ou BERT pour analyser des documents, en gérant des billions de paramètres efficacement.
Qu’est-ce que l’attention multi-tête ?
C’est un mécanisme où plusieurs “têtes” calculent l’attention en parallèle, capturant divers aspects des relations entre mots pour une représentation plus riche.
Les transformeurs fonctionnent-ils seulement pour le texte ?
Non, des variantes comme ViT traitent des images, et des modèles multimodaux comme Gemini gèrent texte, images et vidéos simultanément.
Combien coûte l’entraînement d’un transformeur ?
Pour un grand modèle, cela peut atteindre des millions d’euros en ressources cloud, mais des versions open-source comme ceux de Hugging Face réduisent les coûts pour les PME.